
Decidi comparar as respostas do Mistral, do Gemini e do ChatGPT e fazê-los responderem a um probleminha de lógica que fiz há um tempo e achei muito divertido.
SPOILER: se você quiser tentar resolver o enigma sozinho, não leia as respostas! :)

O objetivo é:
- Descobrir quem é o culpado
- Descobrir qual é a cor da camisa do culpado
Anexei a imagem e mandei o prompt básico para os três modelos:
"Usando as dicas da imagem anexada, responda:
1) Qual é o nome do culpado?
2) Que cor o culpado está vestindo?"
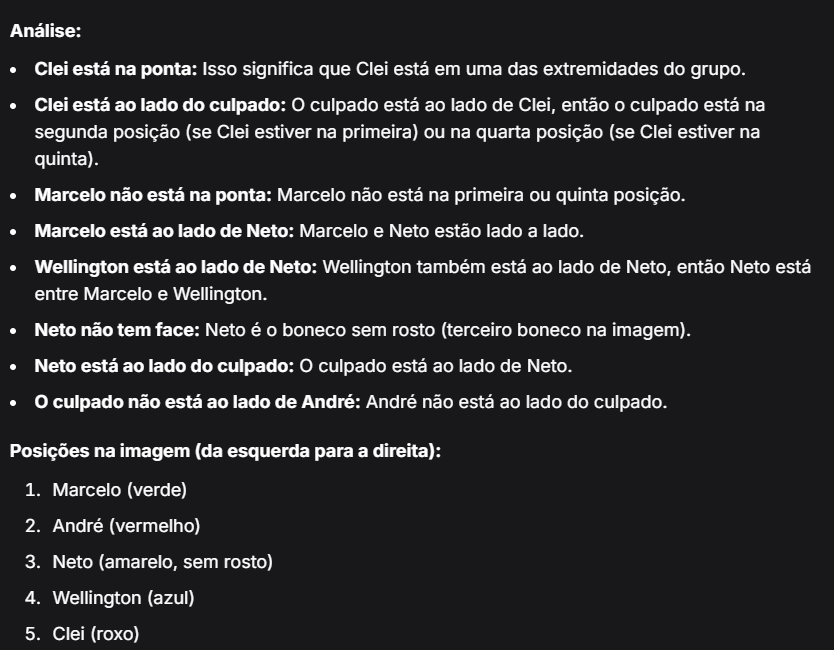
Mistral:
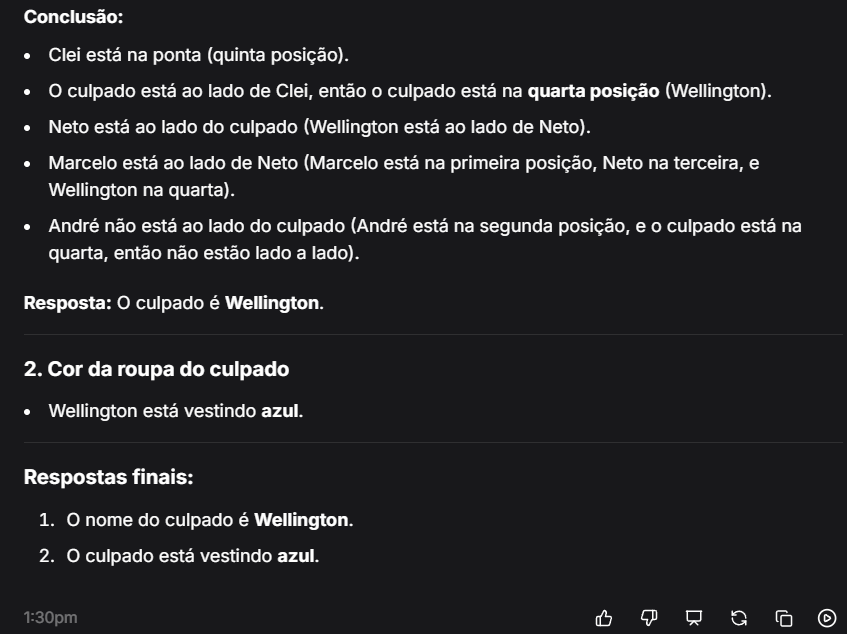
Gemini:


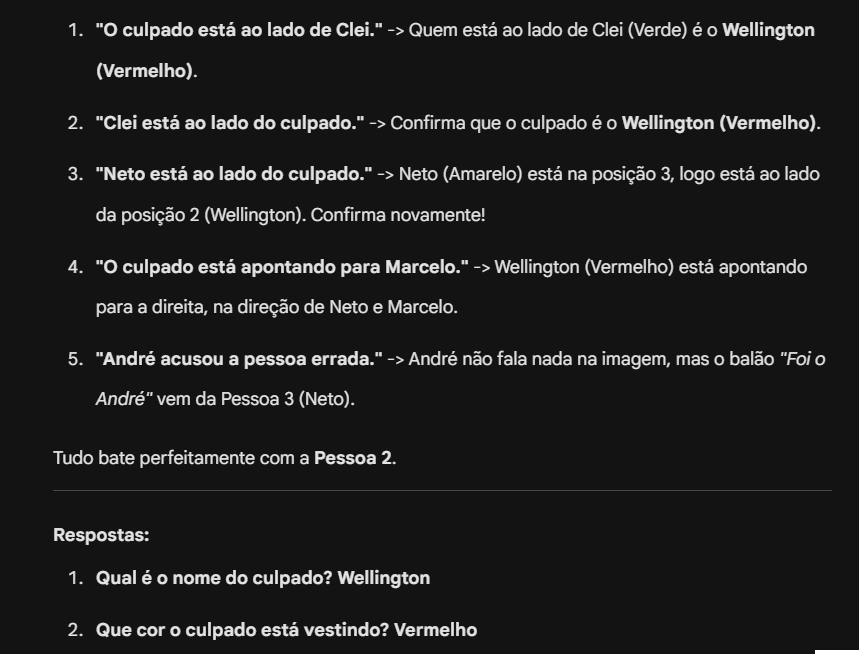
ChatGPT:
Nessa primeira etapa, com o prompt mais básico, todos os modelos acertaram que Wellington era o culpado, mas apenas o Mistral acertou a cor da camisa, que é azul.
Agora, incrementei o prompt com as instruções mais detalhadas:
"Analise a imagem anexada e use as dicas para responder às seguintes perguntas, usando o seguinte procedimento:
(1) Primeiramente, analise as dicas uma por uma e considere se a dica é potencialmente relevante
(2) Em segundo lugar, combine as dicas relevantes para raciocinar a resposta correta à pergunta
Perguntas:
1) Qual é o nome do culpado?
2) Que cor o culpado está vestindo?"
O Gemini seguiu com o mesmo estilo de raciocínio da resposta anterior, mas dessa vez chegou à conclusão correta: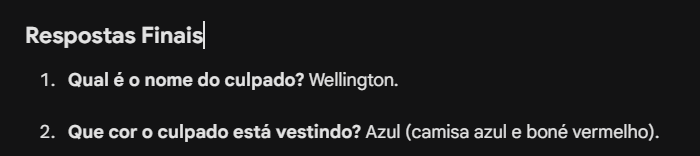
O ChatGPT, apesar de evoluir a linha de raciocínio, continua dando a resposta errada para a cor:



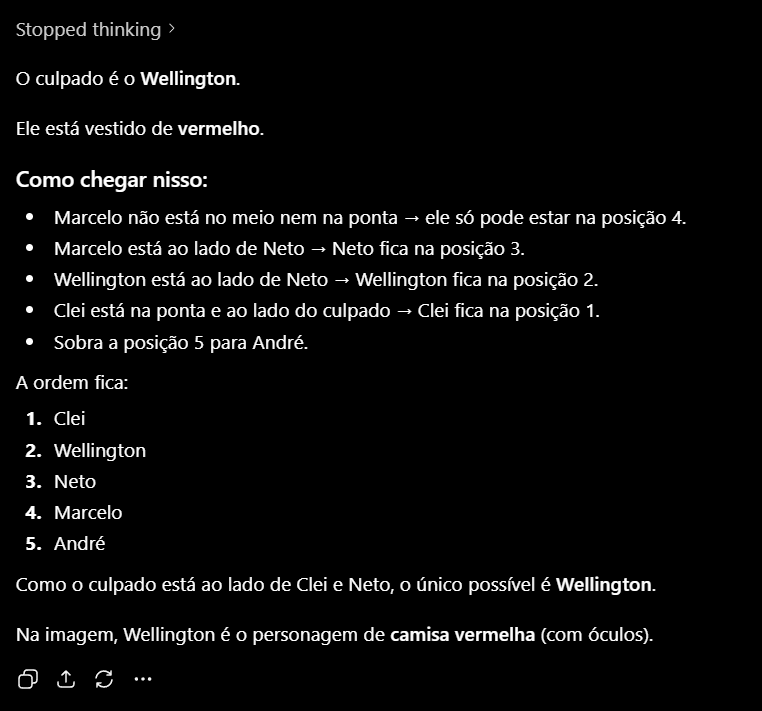
Resolvi incrementar o prompt mais uma vez, para ver se o ChatGPT consegue acertar:
"Analise a imagem anexada e use as dicas para responder às seguintes perguntas, usando o seguinte procedimento:
(1) Primeiramente, analise as dicas uma por uma e considere se a dica é potencialmente relevante
(2) Em segundo lugar, combine as dicas relevantes para raciocinar a resposta correta à pergunta
(3) Por último, revise se sua lógica está correta e se atente a todos os detalhes possíveis. Presuma que você pode ter errado em alguma das suas suposições, e só depois dê a resposta.
Perguntas:
1) Qual é o nome do culpado?
2) Que cor o culpado está vestindo?"
Mesmo com o novo prompt, o ChatGPT continua errando: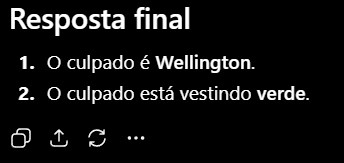
Interessante ver como o modelo "mais famoso" de todas as LLMs é o único que não acerta! Fica o alerta para quando usarmos esses modelos para resolução de questões, sempre revisarmos, porque as LLMs nunca estão 100% corretas e podem cometer erros.

