Tem uma forma mais rápida de criar a coluna com numpy
import numpy as np
dados['possui_suite'] = np.where(dados['Suites'] > 0, 'sim', 'não')
Numa base de dados grande é bem mais performatico que apply.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Tem uma forma mais rápida de criar a coluna com numpy
import numpy as np
dados['possui_suite'] = np.where(dados['Suites'] > 0, 'sim', 'não')
Numa base de dados grande é bem mais performatico que apply.


Oi, Marcelo! Como vai?
Agradeço por compartilhar essa sugestão com a comunidade Alura. Sua observação sobre a forma de criar coluna condicional com numpy é relevante e vale ser destacada para todos que trabalham com bases de dados grandes.
O uso do np.where() realmente traz um ganho significativo de performance em bases maiores quando comparado ao apply(). Ao importar numpy com import numpy as np e aplicar o np.where(), como no exemplo abaixo, você aproveita operações vetorizadas que processam os dados de forma mais rápida e eficiente:
dados['possui_suite'] = np.where(dados['Suites'] > 0, 'sim', 'não')
Essa abordagem é bastante utilizada em cenários de análise de dados com Pandas e NumPy, quando trabalhamos com grandes volumes de informação.
Uma dica complementar é usar o método astype() para criar colunas binárias de forma simples e igualmente performatica. Veja este exemplo:
dados['possui_suite'] = (dados['Suites'] > 0).astype(str)
Nesse caso, o código verifica se o valor da coluna Suites é maior que 0 e transforma o resultado em texto. Essa técnica também evita loops explícitos e melhora bastante o desempenho em uma base grande, sendo uma alternativa rápida e elegante ao apply().
Ótima contribuição, Marcelo. Dicas como essa enriquecem muito o aprendizado coletivo da comunidade.
Você já chegou a comparar o tempo de execução entre o np.where(), o astype() e o apply() em alguma base de dados grande para medir a diferença real de performance?
Oi Monalisa,
Obrigado pelo feedback, esta forma que você mostrou eu penso que tem um overhead de transformar para "sim"/ "não" com um np.where depois ou map, então penso que não é mais performático. e talvez sem o astype sendo puramente bool pode ser mais performático, vamos fazer o teste que, desafio aceito:
import pandas as pd
import numpy as np
import timeit
# 10 milhões de linhas com numeros aleatorios
n = 10_000_000
df = pd.DataFrame({'numero': np.random.randint(-1, 2, size=n)})
# Teste com np.where
def test_np_where():
return np.where(df['numero'] > 0, 'sim', 'não')
# Teste com astype (Note: para mapear para 'sim'/'não' exige um passo extra)
def test_astype():
# .astype(str) apenas converte True/False para "True"/"False" strings,
# se você quer "sim"/"não", o np.where ou .map é necessário.
# Vamos testar a conversão direta para comparação:
return (df['numero'] > 0).astype(str)
# Teste com astype (Note: para mapear para 'sim'/'não' exige um passo extra)
def test_sem_astype():
# .astype(str) apenas converte True/False para "True"/"False" strings,
# se você quer "sim"/"não", o np.where ou .map é necessário.
# Vamos testar a conversão direta para comparação:
return (df['numero'] > 0)
# Teste com .apply()
def test_apply():
return df['numero'].apply(lambda x: 'sim' if x > 0 else 'não')
# Executando os testes
print(f"Executando benchmarks com {n:,} linhas...\n")
t1 = timeit.timeit(test_np_where, number=3)
print(f"np.where: {t1/3:.4f} segundos (média de 3 execuções)")
t2 = timeit.timeit(test_astype, number=3)
print(f"astype: {t2/3:.4f} segundos (média de 3 execuções)")
t3 = timeit.timeit(test_sem_astype, number=3)
print(f"Sem astype: {t3/3:.4f} segundos (média de 3 execuções)")
t4 = timeit.timeit(test_apply, number=3)
print(f"apply: {t4/3:.4f} segundos (média de 3 execuções)")
Resultados:
Executando benchmarks com 10,000,000 linhas...
np.where: 0.2719 segundos (média de 3 execuções)
astype: 2.7610 segundos (média de 3 execuções)
Sem astype: 0.0109 segundos (média de 3 execuções)
apply: 2.4380 segundos (média de 3 execuções)
Se pegarmos o método mais lento como referencia, vemos o impacto da forma vetorizada e do processamento linha a linha.
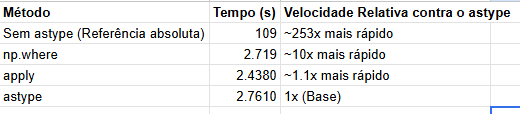
Deste teste simples podemos concluir que:
E talvez, no caso de arquivos grandes talvez outra ferramenta seja mais adequada.
Valeu o feedback, espero ter contribuido humildemente aqui, algum colega pode ser melhor forma de ver isso elevar o nível.
ps: Será que o que colcoamos aqui no fórum alimentar o RAG da LURI ou de alguma IA de resposta automática?