Olá, Vinicius. Como vai?
Excelente contribuição para a comunidade do fórum! É muito gratificante ver estudantes explorando os nós de código do n8n para aplicar soluções em diferentes linguagens. Trazer o equivalente em Python adiciona um valor gigantesco para quem já vem da trilha de Data Science e prefere manipular estruturas de dados com a sintaxe do Python.
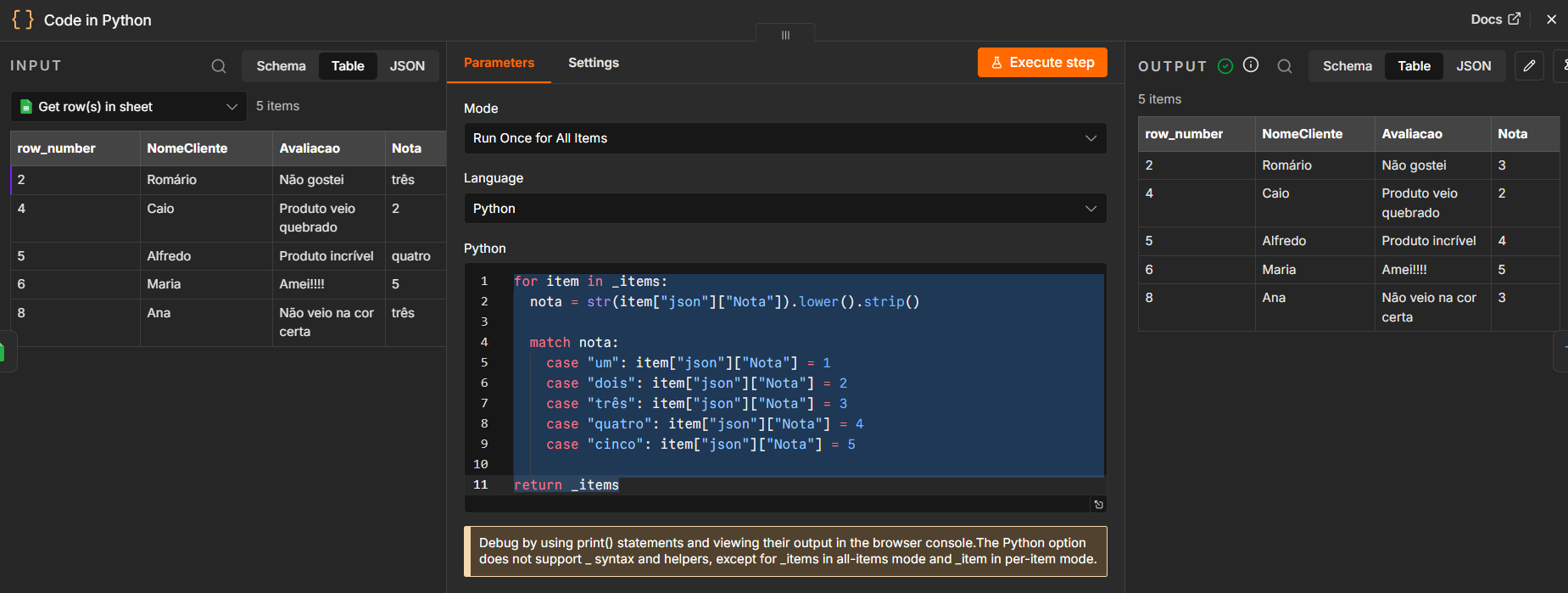
Analisando a sua imagem, o seu código rodou perfeitamente e resolveu com precisão o problema de padronização de dados da planilha intermediária (transformando as strings de texto "três", "quatro" em números inteiros como 3 e 4). O uso dos métodos .lower() e .strip() foi uma ótima prática preventiva para limpar espaços extras e padronizar o caso das letras antes de fazer a checagem.
Como o seu objetivo foi compartilhar essa sugestão e trazer novas perspectivas, quero sugerir duas abordagens alternativas de refatoração para esse mesmo script que podem deixar o seu fluxo de automação no n8n ainda mais performático ou conciso:
1. Abordagem com Dicionários (Mais Limpa e Rápida)
Embora a estrutura de correspondência estrutural de padrões match/case (introduzida no Python 3.10) funcione perfeitamente, no universo Python é uma prática extremamente comum utilizar um dicionário como um mapa de conversão (lookup table).
Isso elimina a repetição de várias linhas de condicionais e torna a manutenção do código muito mais simples se novas notas surgirem no futuro. Além disso, o método .get() do dicionário permite definir um valor padrão caso a nota recebida não esteja mapeada (por exemplo, se já vier como número):
# Criando um dicionário de mapeamento
mapa_notas = {
"um": 1,
"dois": 2,
"três": 3,
"quatro": 4,
"cinco": 5
}
for item in _items:
nota_texto = str(item["json"]["Nota"]).lower().strip()
# Se a palavra estiver no dicionário, substitui pelo número.
# Caso contrário, mantém o valor original
item["json"]["Nota"] = mapa_notas.get(nota_texto, item["json"]["Nota"])
return _items
2. Otimização Direta do n8n (Sem Código)
Como uma curiosidade técnica sobre a ferramenta, vale destacar que o n8n possui um nó nativo específico para esse tipo de tarefa chamado Data Transformation (antigo Edit Fields/Set) ou o nó Switch.
Para automações simples de produção, dar preferência aos nós visuais nativos em vez de blocos de código (Code Node) ajuda no desempenho geral da ferramenta, além de facilitar a leitura do fluxo por outros membros da equipe que não dominam linguagens de programação.
Parabéns pelo compartilhamento e pela iniciativa de enriquecer o material das aulas! Códigos limpos assim ajudam muito a destravar outros alunos.
Espero que possa ter lhe ajudado!