Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!



Olá, Nicole. Como vai?
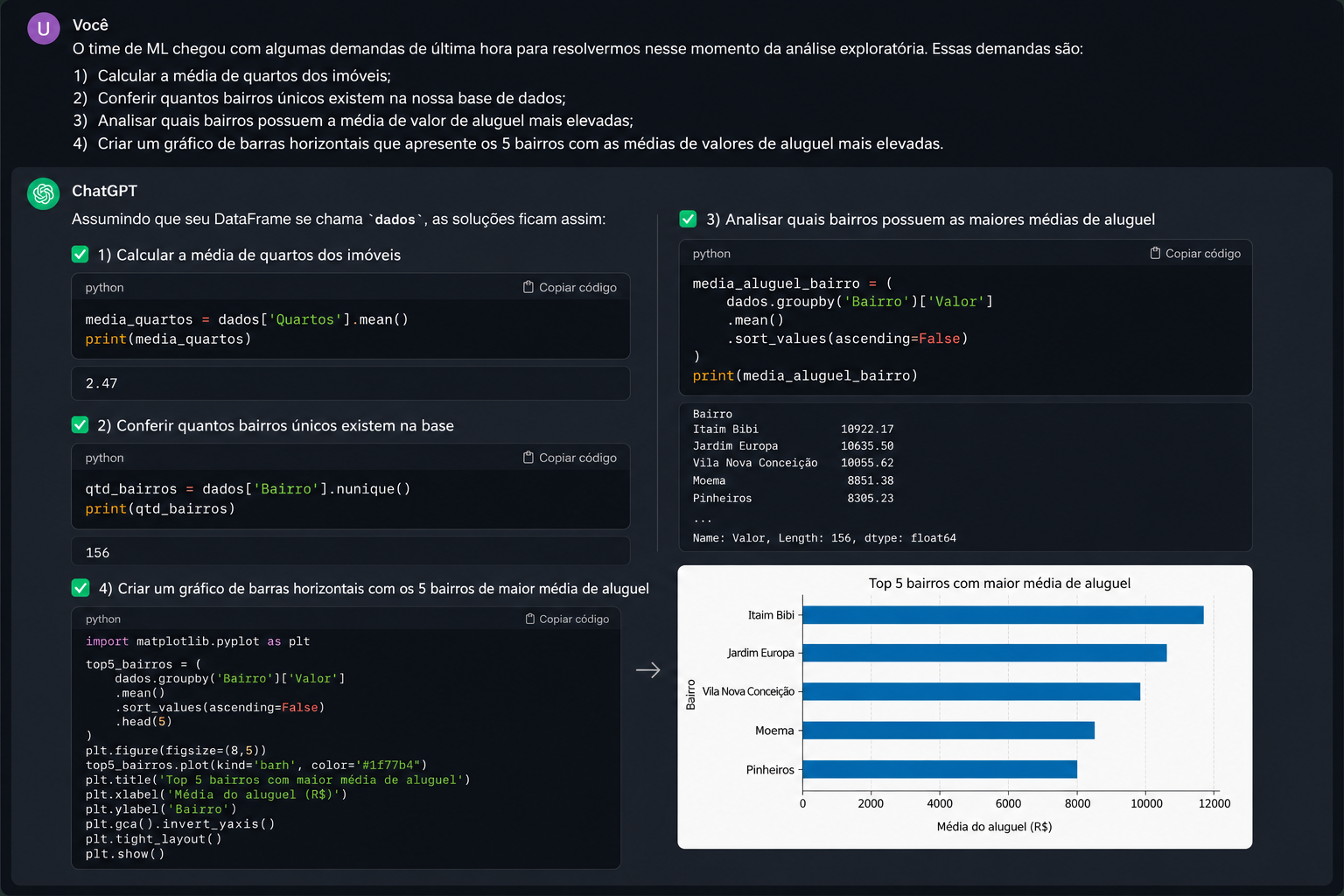
Excelente postagem demonstrando a resolução completa do desafio de análise exploratória com o Pandas! Sua interação com o ChatGPT foi muito bem estruturada, e a resposta gerada trouxe códigos limpos, eficientes e de altíssima qualidade técnica. O gráfico de barras horizontais gerado no final ficou ótimo e perfeitamente legível.
Como você cobriu todos os requisitos com sucesso, gostaria de trazer um complemento de boas práticas técnicas que podem otimizar ainda mais o seu código e deixar os seus relatórios mais profissionais no dia a dia de Data Science:
dados.groupby('Bairro')['Valor'].mean(). Uma excelente prática de performance, principalmente para bases de dados massivas, é filtrar a coluna que você quer calcular antes de aplicar a função agregadora, ou seja: dados.groupby('Bairro')[['Valor']].mean(). Isso ajuda o Pandas a alocar menos memória durante a operação.plt.gca().invert_yaxis() para garantir que o bairro com maior média ficasse no topo. Essa é uma solução perfeita! Outra alternativa comum é aplicar o método .sort_values(ascending=True) na hora de selecionar o head(5). Dessa forma, o maior valor fica por último no conjunto de dados e, ao plotar o gráfico de barras horizontais (barh), o Matplotlib naturalmente o posiciona no topo, dispensando a necessidade de inverter o eixo manualmente.Para ilustrar como ficaria o código do item 4 aplicando essas pequenas otimizações de encadeamento de métodos (method chaining), veja o exemplo abaixo:
# Otimizando o agrupamento e a ordenação para o gráfico
top5_bairros = (
dados.groupby('Bairro')[['Valor']]
.mean()
.sort_values(by='Valor', ascending=True) # Menor para o maior para o barh plotar o maior no topo
.tail(5) # Pega os 5 maiores da ponta inferior
)
# Renderizando o gráfico de forma simplificada
top5_bairros.plot(kind='barh', color='#1f77b4', figsize=(8, 5))
plt.title('Top 5 bairros com maior média de aluguel')
plt.xlabel('Média do aluguel (R$)')
plt.ylabel('Bairro')
plt.tight_layout()
plt.show()
O uso da função .nunique() no item 2 também foi excelente, pois ela ignora automaticamente valores nulos (NaN), entregando a contagem exata de bairros reais distintos que existem na base.
Continue explorando o potencial das IAs para acelerar os seus códigos e compartilhando os seus resultados aqui no fórum!
Espero que possa ter lhe ajudado!