Olá, Aristóteles! Como vai?
Parabéns pela resolução primorosa de toda a sequência de desafios da biblioteca Pandas! Seus códigos rodam perfeitamente no Google Colab, e os resultados encontrados fazem total sentido analítico.
Gostaria de destacar alguns pontos excelentes do seu trabalho e trazer um detalhe muito importante sobre a interpretação do seu gráfico de barras que vai te ajudar a evitar bugs visuais nos seus próximos projetos de Data Science.
Análise dos Acertos Tecnológicos
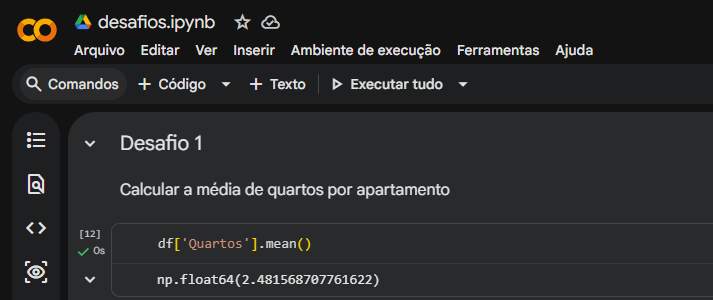
- Desafio 1 (Média): Você mandou muito bem ao utilizar a função
round(..., 2) no seu post de texto. Arredondar valores de ponto flutuante com muitas casas decimais é uma ótima prática para deixar relatórios amigáveis. - Desafio 2 (Dados Únicos): O método
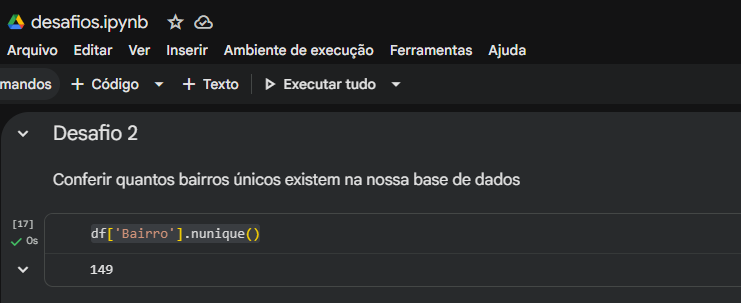
.nunique() é perfeito para entender a cardinalidade da sua variável categórica (Bairro), confirmando que existem 149 regiões diferentes mapeadas. - Desafio 3 (Agrupamento): Sua lógica combinando
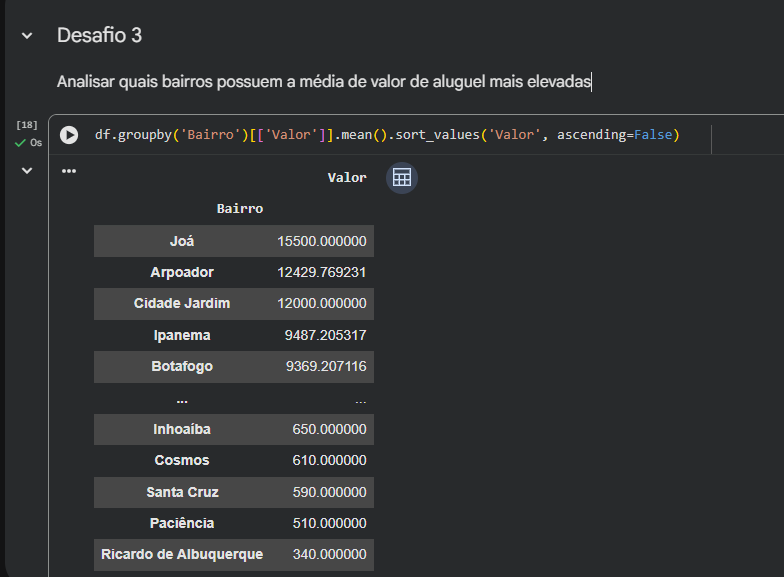
.groupby(), .mean() e .sort_values() com o parâmetro ascending=False isolou e ordenou com precisão os aluguéis do maior para o menor.
Um Detalhe Importante: A Pegadinha do kind='barh'
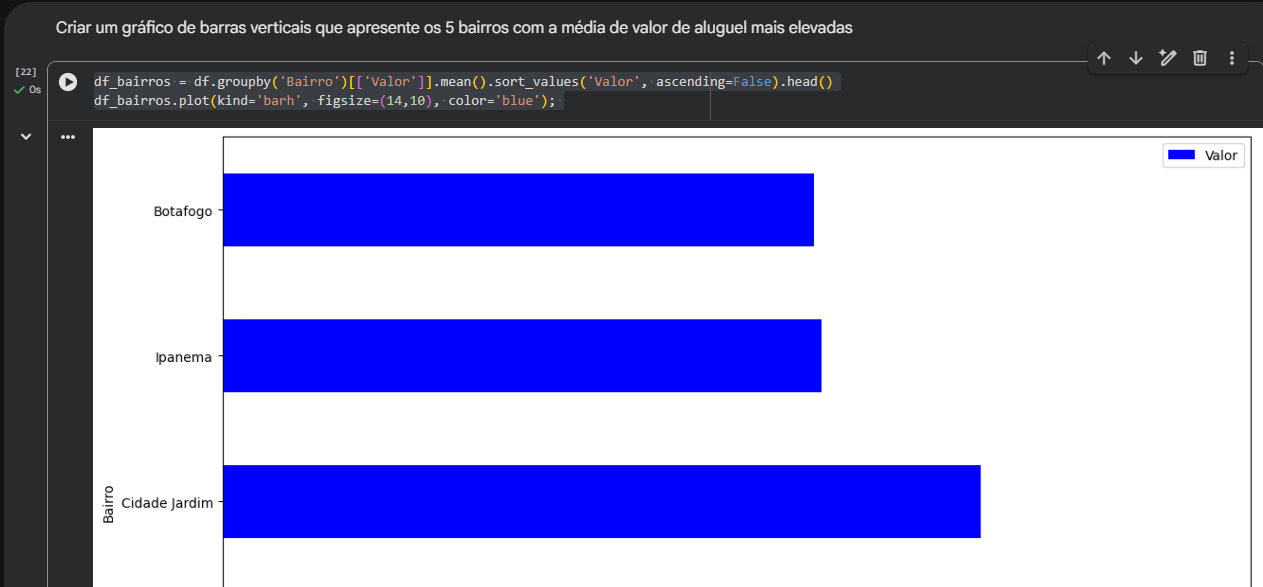
Ao olhar para o código e para o resultado visual do seu Desafio 4, você executou exatamente o que foi proposto na aula. Porém, repare em um comportamento curioso do Pandas ao plotar gráficos de barras horizontais (barh):
Se você olhar a tabela do seu Desafio 3, o bairro com a maior média é Joá (R$ 15.500,00), seguido por Arpoador e Cidade Jardim. No entanto, quando plotamos um gráfico de barras horizontais utilizando diretamente o .head(), o Pandas começa a desenhar as barras de baixo para cima.
Por isso, na sua imagem, o bairro Cidade Jardim aparece na base da plotagem com a maior barra, enquanto Joá e Arpoador ficaram "escondidos" na parte superior que acabou sendo cortada pelo tamanho da figura (figsize).
Como ajustar isso para o gráfico ficar perfeito?
Para que o seu gráfico de barras horizontais exiba o topo do ranking corretamente no topo do gráfico, basta aplicar o método .invert_yaxis() do Matplotlib ou utilizar o método .sort_values() de forma crescente antes do .head(). Veja como corrigir a lógica do plot:
# Invertemos para ordem crescente antes do head para que os maiores fiquem por último na tabela...
df_bairros = df.groupby('Bairro')[['Valor']].mean().sort_values('Valor', ascending=True).tail(5)
# ...e ao plotar horizontalmente, o Pandas colocará o maior valor no topo do gráfico!
df_bairros.plot(kind='barh', figsize=(14, 10), color='blue')
Dessa forma, o bairro Joá ocupará o topo do seu gráfico de barras de maneira muito mais intuitiva para quem for ler o seu relatório.
Continue com esse excelente ritmo de estudos e compartilhando suas práticas aqui no fórum!
Espero que possa ter lhe ajudado!