import pandas as pd
uri = r'\raw\usina.csv'
df = pd.read_csv(uri, sep=',')
df.head()
y = df['PE']
X = df.drop('PE', axis=1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.35, random_state=42)
import seaborn as sns
sns.pairplot(data=df, y_vars=['PE'], x_vars=['AT', 'V', 'AP', 'RH'])
import statsmodels.api as sm
X_train = sm.add_constant(X_train)
modelo = sm.OLS(y_train, X_train).fit()
print(modelo.summary())
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif_1 = pd.DataFrame()
vif_1["variavel"] = X_train.columns
vif_1["vif"] = [variance_inflation_factor(X_train[X_train.columns].values, i) for i in range(len(X_train.columns))]
print(vif_1)
import plotly.express as px
y_previsto_train = modelo.predict(X_train)
fig = px.scatter(x=y_previsto_train, y=y_train, title='Previsão X Real', labels={'x':'Preço previsto','y':'Preço real'})
fig.show();
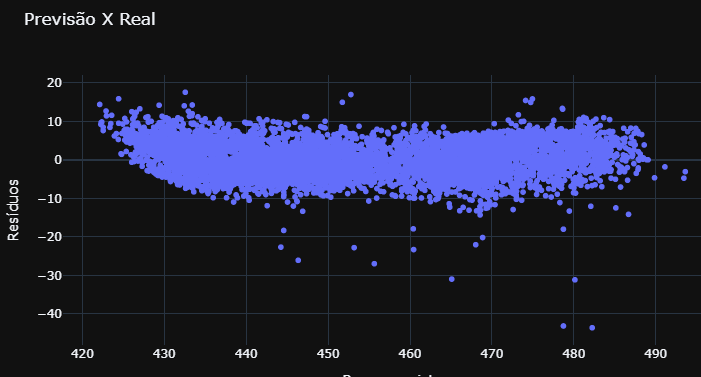
residuos = modelo.resid
fig = px.scatter(x=y_previsto_train, y=residuos, title='Previsão X Real', labels={'x':'Preço previsto','y':'Resíduos'})
fig.show();
Para este processo não houve heterocedasticidade