Os doi comandos foram testados em duas IAs diferentes, o primeio foi utilizado no Gemini e o segundo no ChatGPT.

Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

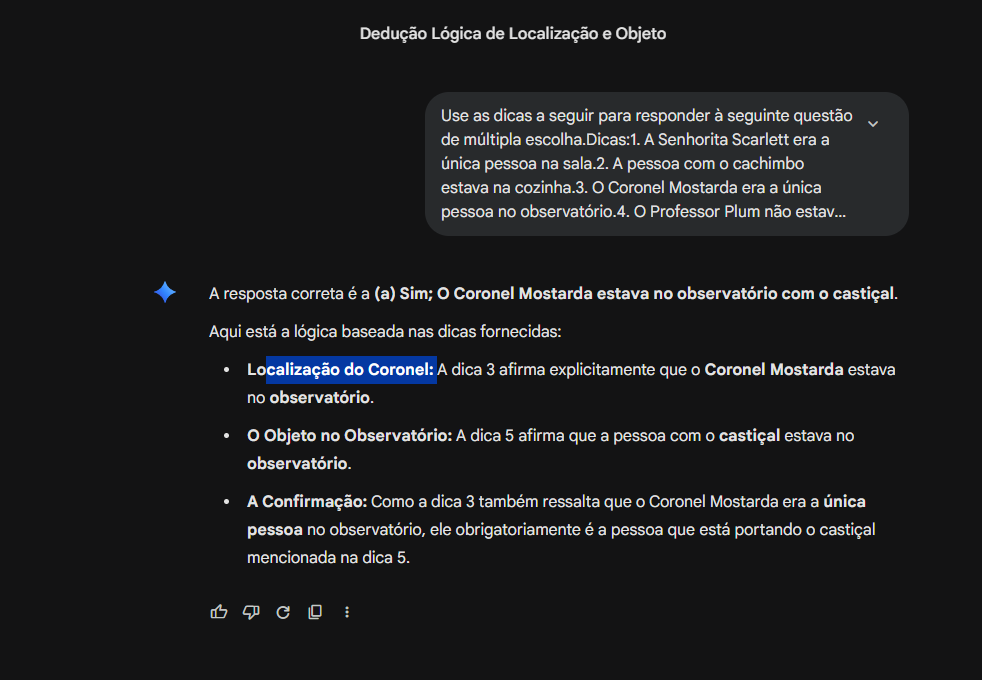
Os doi comandos foram testados em duas IAs diferentes, o primeio foi utilizado no Gemini e o segundo no ChatGPT.


Oi, Luiz, como vai?
Testar os dois prompts em IAs diferentes foi uma escolha interessante, pois além de observar o impacto da engenharia de prompt na qualidade da resposta, dá para notar também como modelos distintos reagem de forma diferente à mesma instrução.
Olhando os resultados, a diferença é bem evidente. No Gemini, com o prompt mais simples, a resposta chegou à conclusão correta, mas o raciocínio foi mais direto e menos detalhado. Já no ChatGPT, com o prompt estruturado em subtarefas, o modelo explicitou cada etapa do raciocínio, avaliando dica por dica antes de chegar à conclusão. Esse tipo de transparência no processo é justamente o que se busca ao aplicar os princípios de engenharia de prompt.
Parabéns pelo exercício e obrigado por compartilhar as duas comparações.
O fórum está à disposição sempre que precisar.