
# Definindo y e X
y = hoteis['Preco']
X = hoteis.drop(columns = 'Preco')
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 230)
df_train = pd.DataFrame(data = X_train)
df_train['Preco'] = y_train
X_train = sm.add_constant(X_train)
# Criando o modelo de regressão (sem fómula): saturado
modelo_1 = sm.OLS(y_train,
X_train[['Estrelas', 'ProximidadeTurismo', 'Capacidade']]).fit()
# Modelo sem a ProximidadeTurismo
modelo_2 = sm.OLS(y_train,
X_train[['Estrelas','Capacidade']]).fit()
# Modelo sem as ProximidadeTurismo e Capacidade
modelo_3 = sm.OLS(y_train,
X_train[['Estrelas']]).fit()
print("Modelo 1: ", modelo_1.rsquared)
print("Modelo 2: ", modelo_2.rsquared)
print("Modelo 3: ", modelo_3.rsquared)
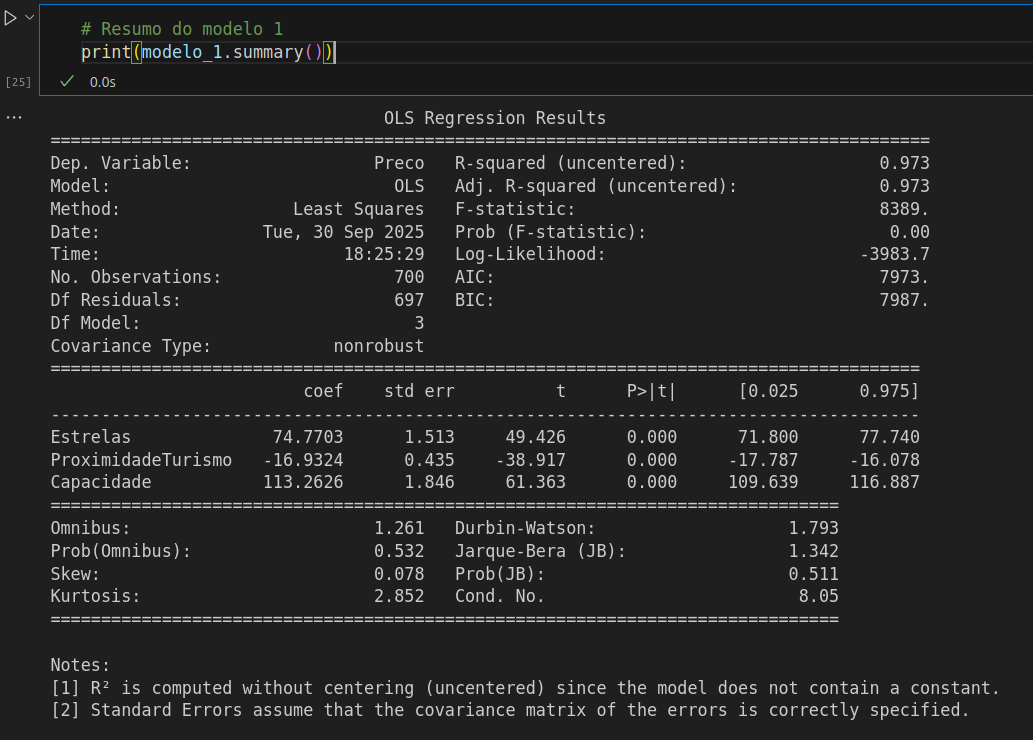
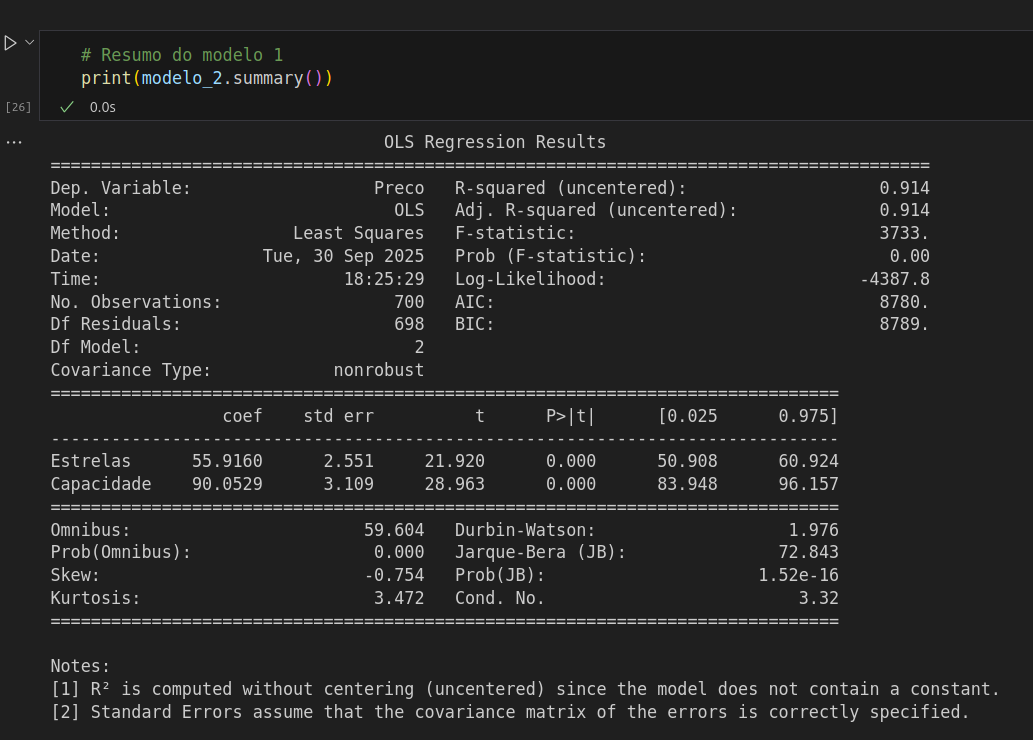
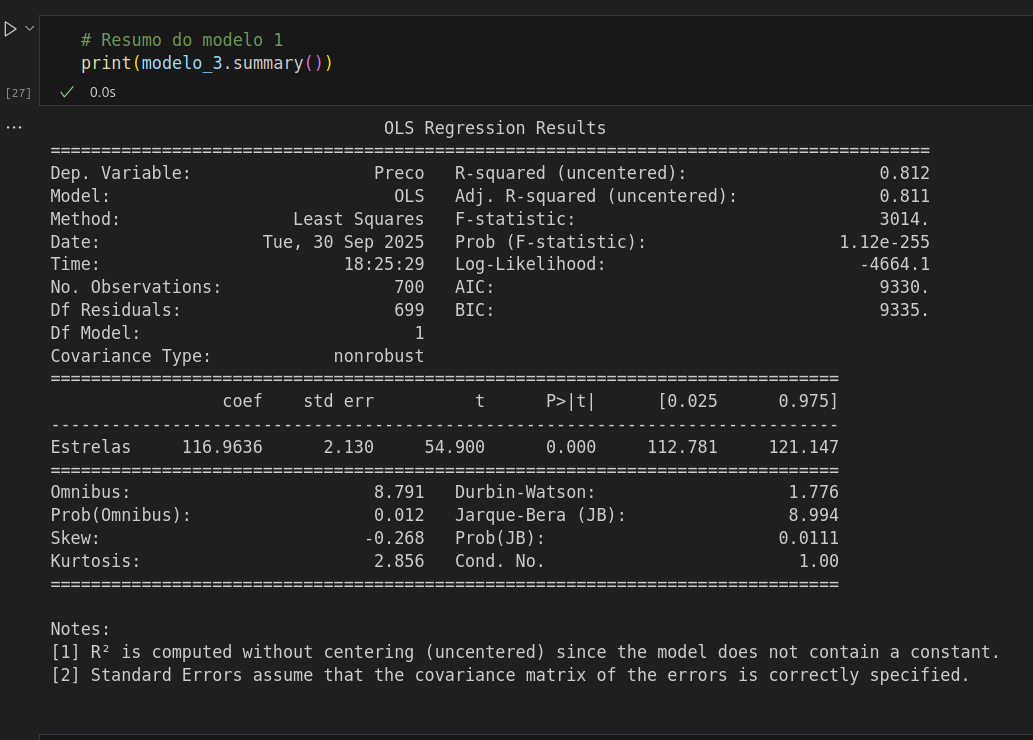

Eu vi que diverge um pouco da resposta do instrutor e dos colegas, eu errei em alguma parte, tem como melhorar?

