
Eu acabei de assistir a aula dois e achei as visualizações confusas utilizando apenas dois ou três atributos, além do fato de que perdemos todas informações dos outros atributos, o que pode nos levar a conclusões erradas.
Como este curso vem logo após o curso sobre dados multidimensionais na formação de Machine Learning achei que seria interessante utilizar alguma técnica como o PCA ou TSNE ensinadas no curso anterior para conseguirmos visualizar os grupos calculados pelo K-means.
Por exemplo: 1- Gráfico feito na aula com os atributos Intensidade de Cor e Álcool e 4 grupos:
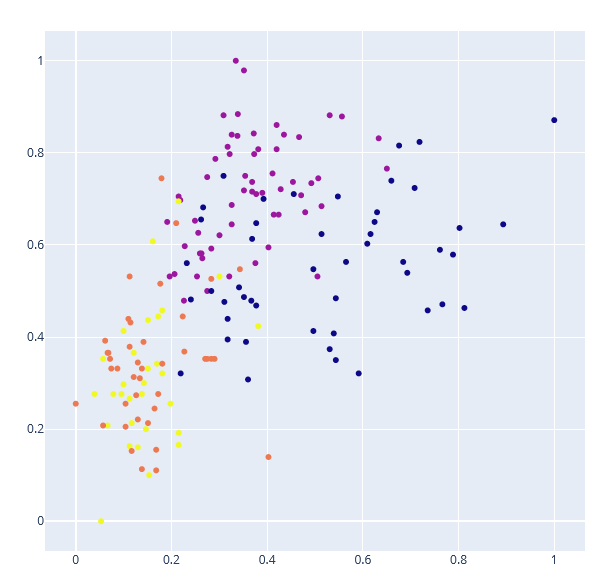
Gráfico feito após a redução de dimensionalidade com o PCA e labels feitos com o K-means da mesma forma:
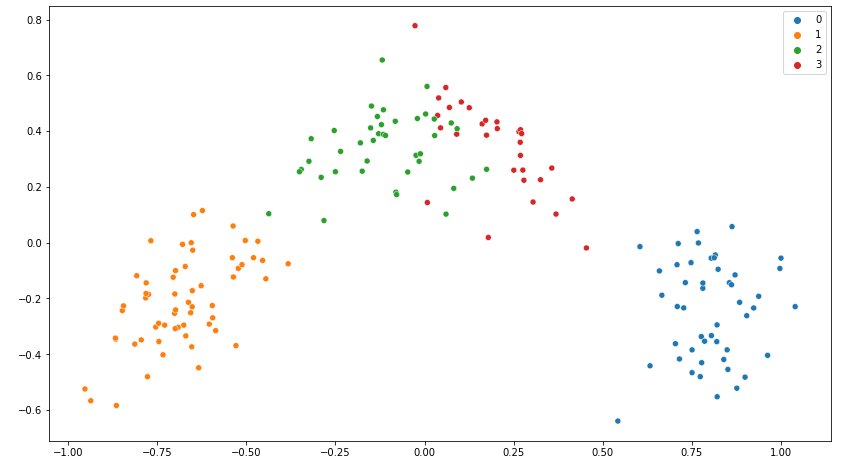
Sei que também há perda de informação ao realizar o PCA, não há como reduzir dimensões sem perder informação, mas perde bem menos do que simplesmente escolhendo atributos específicos, exceto a intenção seja avaliar aqueles atributos. Para analisar os grupos acredito que fique melhor. Ainda mais quando separamos em três grupos: Exemplo da aula:
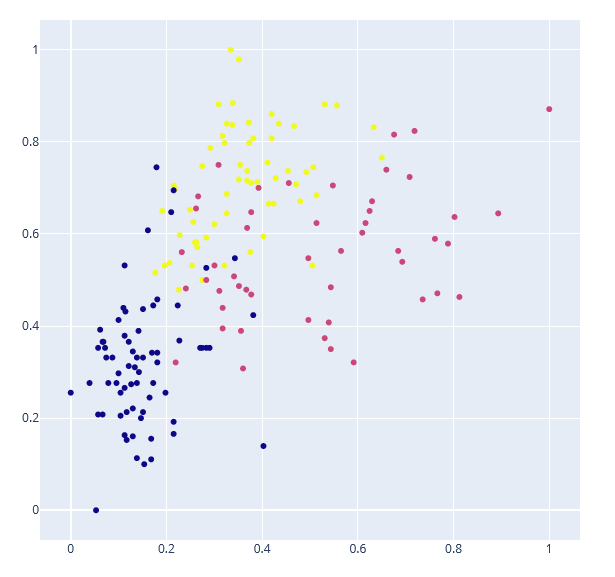
Por essa imagem o professor falou que fazer a divisão em três grupos talvez não fosse o ideal, mas com o PCA a conclusão é exatamente o contrário:
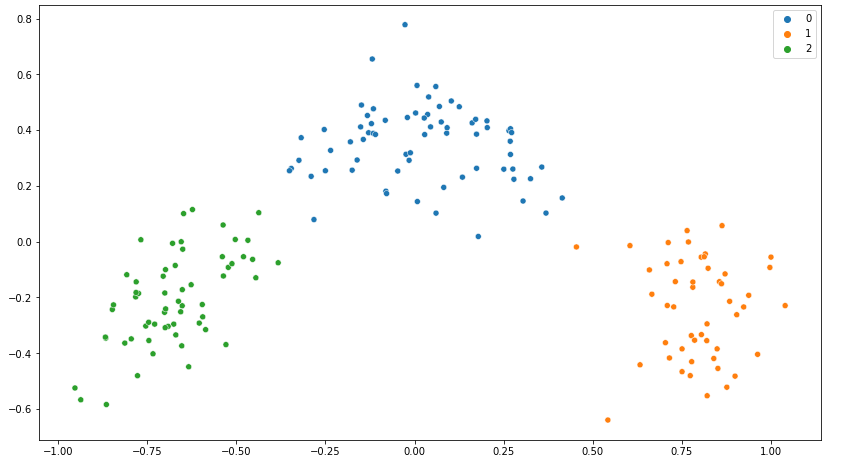
Segue abaixo o código utilizado para quem quiser testar:
from sklearn.decomposition import PCA
import seaborn as sns
pca = PCA(n_components = 2)
df_simpl = pca.fit_transform(df)
plt.figure(figsize=(14, 8))
sns.scatterplot(x = df_simpl[:,0], y = df_simpl[:,1], hue = labels, palette='tab10')
