Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!



Olá, William! Tudo bem?
Sua sugestão é extremamente valiosa para quem trabalha com modelos de Regressão Linear. A verificação da normalidade não é apenas um "capricho" estatístico, mas um pressuposto fundamental para que os testes de hipóteses sobre os coeficientes do modelo sejam válidos.
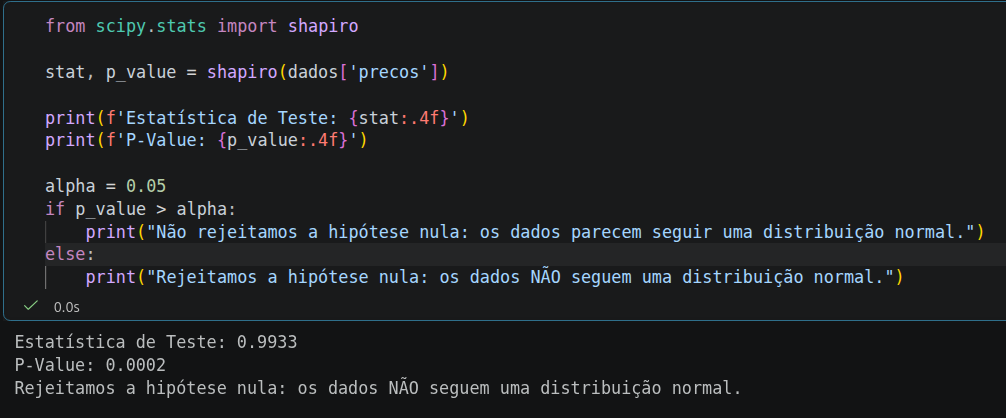
Analisando o código e o resultado que você compartilhou na imagem:
O Teste de Shapiro-Wilk é uma das ferramentas mais robustas para verificar a normalidade em amostras pequenas e médias. No seu resultado, temos informações cruciais:
Como os dados da coluna precos não seguem uma distribuição normal, você pode enfrentar alguns desafios na modelagem direta:
Seu código está muito bem estruturado e legível. Uma pequena melhoria para visualização em projetos de Data Science seria plotar um Histograma ou um Q-Q Plot logo após o teste:
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as stats
# Visualizando a distribuição
sns.histplot(dados['precos'], kde=True)
plt.title('Distribuição de Preços')
plt.show()
# Q-Q Plot para verificar desvios da normalidade
stats.probplot(dados['precos'], dist="norm", plot=plt)
plt.show()
Obrigado por compartilhar essa boa prática com a comunidade! Testar as premissas antes de rodar o modelo evita previsões tendenciosas e garante a robustez da análise.
Uma pergunta para quem está acompanhando: Além do Shapiro-Wilk, alguém aqui costuma usar o teste de D'Agostino-Pearson para amostras maiores?