Fala, David! Tudo certo?
Cara, brigadão por trazer esse ponto com tanto cuidado — tua explicação tá muito bem construída e levanta uma discussão massa.
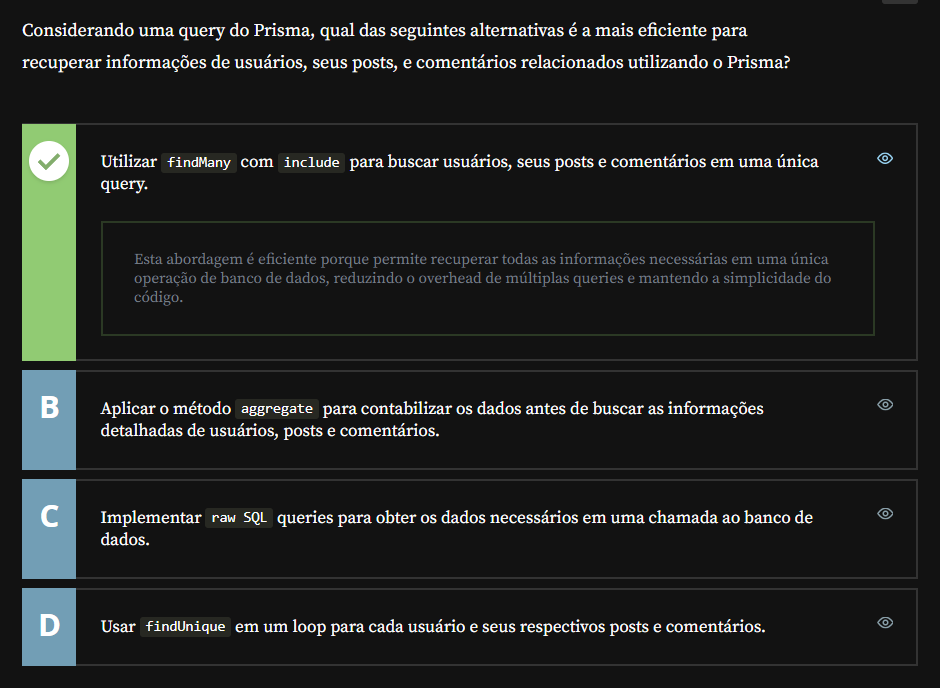
A intenção da questão era puxar mais pro lado da eficiência do desenvolvedor, no sentido de escrever uma única query Prisma usando include e resolver tudo de uma vez só no código — usuários, posts e comentários. A ideia era mostrar como o Prisma facilita esse tipo de consulta completa, sem precisar escrever várias chamadas explícitas.
Mas o teu ponto é super válido: tecnicamente, o Prisma ainda pode fazer mais de uma ida ao banco dependendo do relacionamento e da forma como o include é resolvido por baixo dos panos. Isso varia conforme o motor e a versão — e, de fato, em alguns casos o Prisma executa múltiplas queries em sequência (o que chamam de N+1 mitigado).
Aí entra a diferença entre duas coisas que se confundem fácil: eficiência de desenvolvimento (escrever menos código, com mais legibilidade) vs eficiência de execução (velocidade e uso de recursos no banco). E é nesse ponto que tua análise brilha.
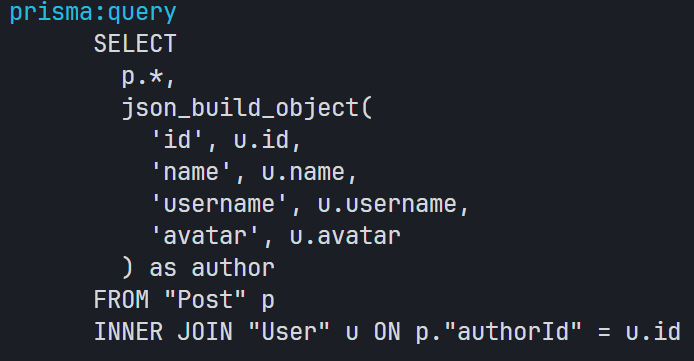
Tu mostrou ali na prática que, em vez de deixar o Prisma montar isso com include (e acabar fazendo duas queries separadas), dá pra montar uma raw query com JOIN e trazer tudo numa consulta só — o que, em bancos com alto volume de dados, costuma ser mais rápido mesmo.
Essa abordagem evita latência dupla (duas idas ao banco), dá mais controle sobre o payload, e costuma ter melhor desempenho quando os índices estão bem ajustados. Já o include, apesar de super prático, pode escalar mal dependendo da quantidade de dados e do número de relacionamentos envolvidos.
Ou seja: tecnicamente falando, a tua query manual com JOIN e json_build_object tende a performar melhor num banco grande, justamente por evitar esse custo de múltiplas chamadas — mesmo que o Prisma tente otimizar por trás.
Então sim: teu ponto é super válido e me ajudou a enxergar que o enunciado podia deixar isso mais claro. Já anotei aqui pra ajustar numa próxima revisão e evitar esse ruído entre o que é “eficiente” pra quem tá escrevendo o código e o que é “eficiente” de fato pra quem tá rodando no banco.
Valeu demais por trazer isso com tanta clareza. Quando tiver mais observações, sugestões, ou até vontade de bater um papo mais técnico, manda ver — ajuda muito a gente a evoluir o conteúdo com quem tá realmente mergulhado no que tá aprendendo.
Tamo junto! Abraço!