
RAG na Saúde: Combatendo Alucinações em Dispositivos Médicos Inteligentes
Por Ricardo Costa Val do Rosario auxiliado por ChatGPT 5.0 Plus
RAG aplicado à Saúde e Dispositivos Médicos Inteligentes (DM IA)
- Modelos de Linguagem de Grande Porte (LLMs), apesar de sua alta capacidade de geração de texto,
sofrem de três limitações críticas:
1. Alucinações,
2. Conhecimento desatualizado,
3. Inacessibilidade a bases privadas e proprietárias.
- O RAG (Retrieval Augmented Generation) surge como a principal arquitetura para mitigar esses riscos,
ao integrar busca semântica em dados reais, privados e auditáveis ao processo de geração de respostas,
garantindo confiabilidade, rastreabilidade e segurança da informação.
Contextualização Clínica
- Na área da saúde, alucinações não representam apenas erros técnicos, mas sim riscos diretos à
vida humana.
- O uso de RAG torna-se um pilar estrutural da Tecnovigilância ao permitir que:
1. Protocolos clínicos reais sejam consultados em tempo real;
2. Laudos e diretrizes institucionais sejam respeitados;
3. Os (DM IA) operem sob bases científicas atualizadas.
Contextualização Ética e Regulatória
- O RAG está diretamente alinhado com:
• LGPD (Brasil),
• HIPAA (EUA),
• ISO 13485 e IEC 62304, pois evita o envio de dados sensíveis para fora da infraestrutura
institucional e garante explicabilidade (XAI) ao indicar a fonte exata da resposta.
Retrieval Augmented Generation (RAG)
- O RAG combina o melhor dos dois mundos: a busca precisa de um motor de busca com a capacidade
de conversação de uma LLM. Assim, temos a busca mais geração, o que nos permite obter respostas
inteligentes e confiáveis.
- A combinação cria um sistema híbrido mais poderoso do que qualquer componente isolado.
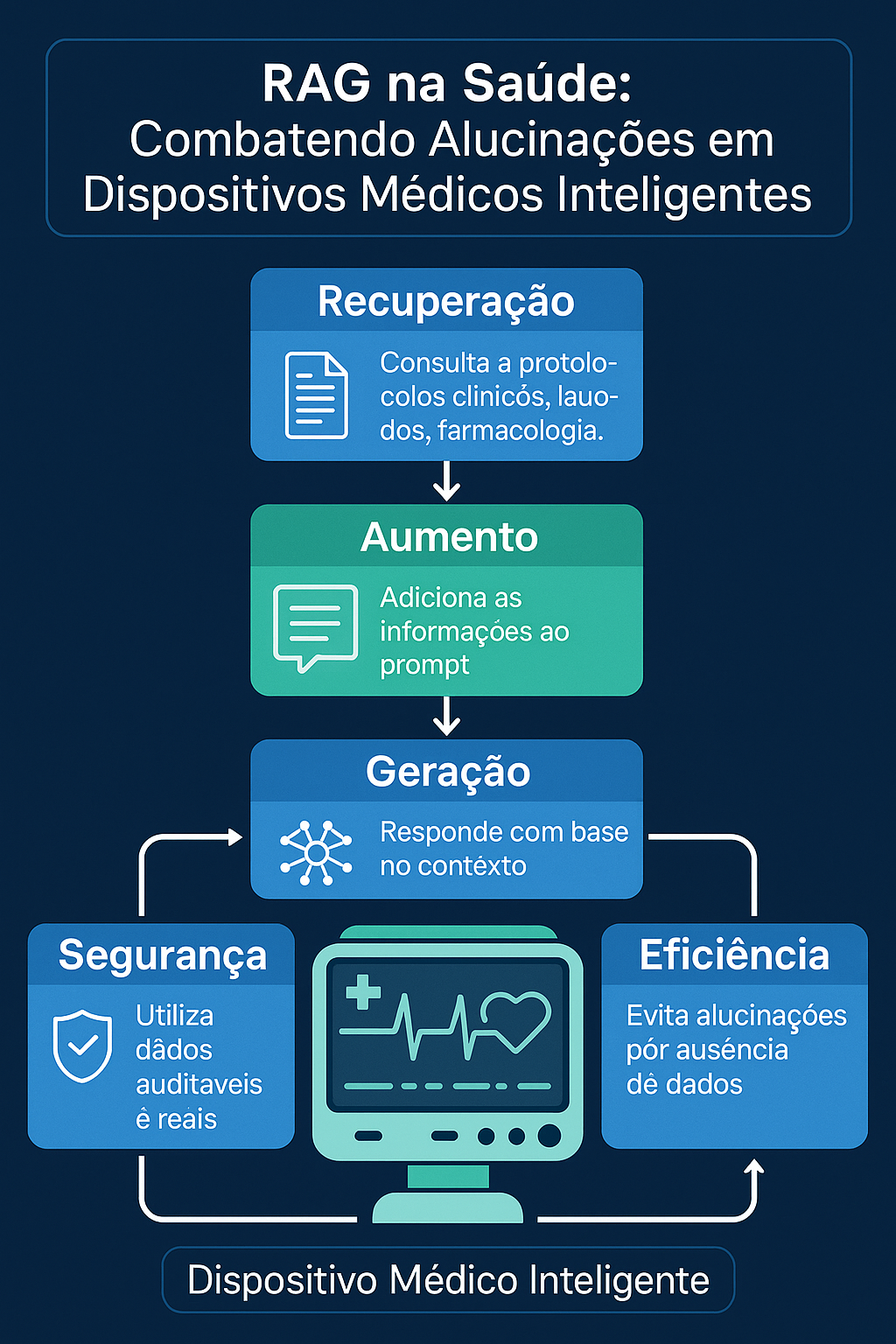
- São três componentes principais:
1. Retrieval (Recuperação): Envolve a busca de informações relevantes em documentos para
responder a uma pergunta. O sistema busca documentos relevantes na base de conhecimento.
2. Augmentation (Aumento): Refere-se à melhoria das capacidades do modelo,
inserindo informações encontradas como contexto no prompt do usuário.
3. Generation (Geração): Refere-se à capacidade natural das LLMs de gerar um texto coerente.
Descrição do processo RAG
1. A primeira etapa é a recuperação, que consiste em encontrar trechos de informações mais relevantes
em documentos para responder a uma pergunta. Ele utiliza, nessa primeira etapa, uma busca semântica,
não apenas palavras-chave.
2. O sistema busca documentos relevantes na base de conhecimento.
3. Em seguida, ele aumenta o prompt do usuário, inserindo as informações encontradas como
contexto.
4. Finalmente, a LLM gera uma resposta com a instrução clara de usar apenas aquele contexto.
5. Todo o processo ocorre de forma automática e em tempo real.
Definindo Alucinações e como evita-lás
Aumentar o prompt significa que ele adiciona informações relevantes ao contexto da pergunta e a
instrução diz respeito a apenas este mesmo contexto, o que é crucial para evitar alucinações,
pois, às vezes, o modelo não sabe a resposta e acaba inventando.
Explorando o aumento do contexto e componentes do RAG
- O truque do RAG é fornecer ao LLM um livro de consulta específico para cada pergunta, permitindo
uma resposta precisa e baseada em fatos.
- O processo envolve uma pergunta do usuário, seguida por uma busca semântica em documentos
relevantes e aumenta o contexto, adicionando documentos ao prompt.
- A LLM responde com base neste contexto específico, gerando uma resposta conforme as informações
existentes.
# Exemplo,
Se apergunta do usuário for sobre a política de devolução para produtos eletrônicos, o sistema recupera
o contexto: produtos eletrônicos podem ser devolvidos em até 30 dias com a nota fiscal, mas itens
danificados não são elegíveis.
A resposta gerada seria: "Nossa política permite a devolução de produtos eletrônicos em até 30 dias,
desde que você apresente a nota fiscal e o produto não esteja danificado.
Componentes essenciais do RAG
incluem os embeds, que são representações numéricas, vetores que capturam o significado semântico
dos textos, permitindo busca por similaridade. Basicamente, são os DNAs da informação. juntamente
com um banco de dados vetorial.
Ao armazenar os dados eles causam a indexação dos embeds para uma busca rápida e eficiente.
# Exemplos incluem FIZE, CHROMA, PINECONE, entre outros.

