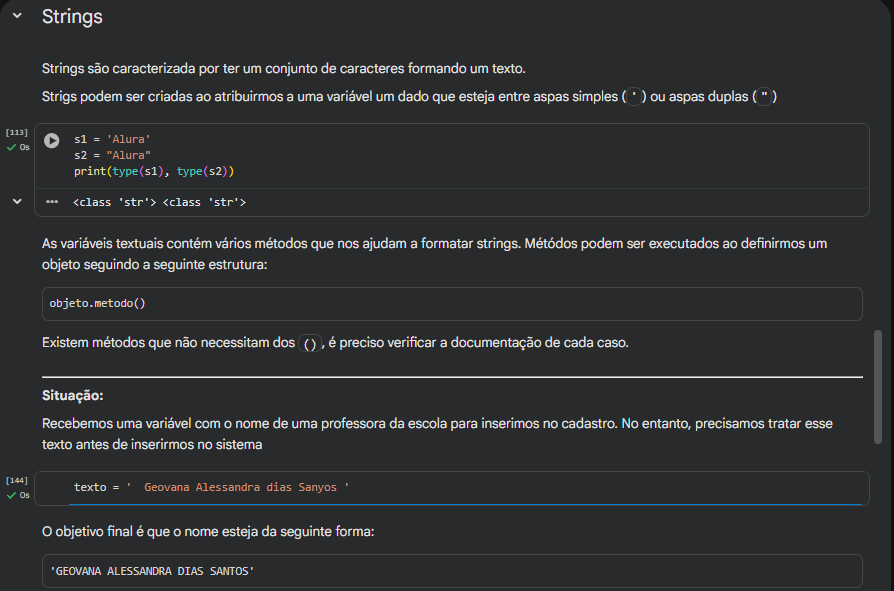
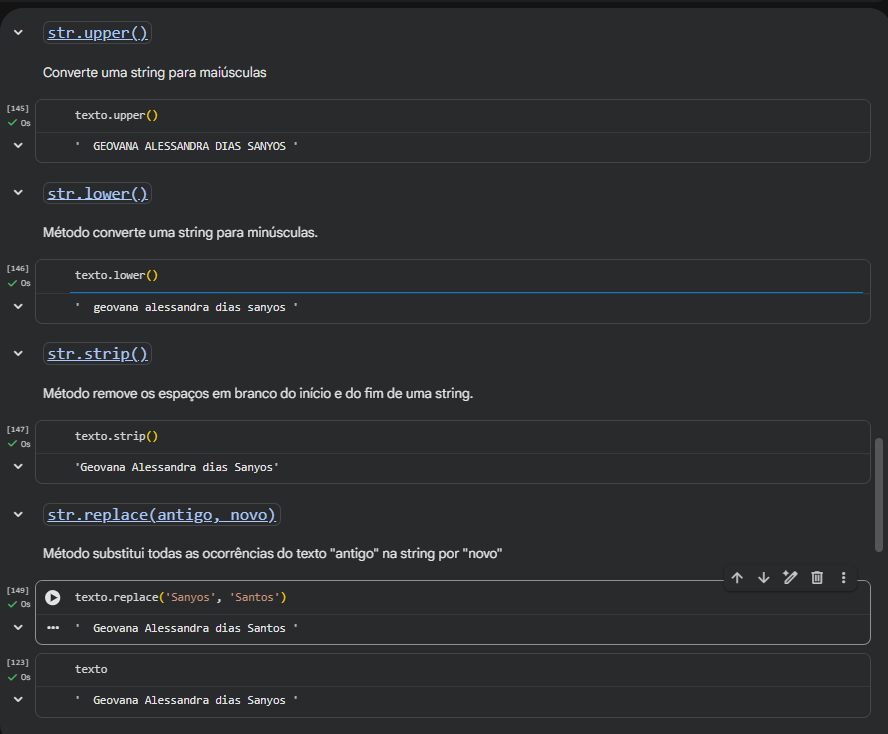
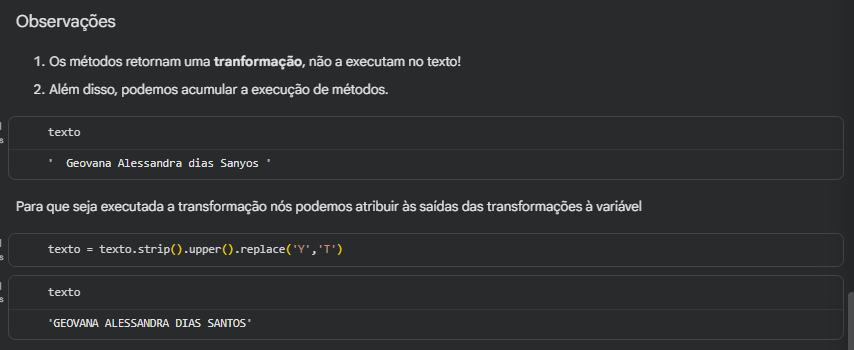
Oi, Maico! Como vai?
Agradeço por compartilhar seu raciocínio com a comunidade. Esse tipo de reflexão faz toda a diferença no aprendizado de strings em Python.
Sua observação sobre a ordem entre .upper() e .replace() no projeto é pertinente. Quando utilizamos o .upper() antes do .replace(), todo o texto passa para caixa alta, e por isso o valor que queremos identificar dentro do .replace() também deve estar em letras maiúsculas para que a substituição funcione corretamente. Caso contrário, o método simplesmente não encontra o trecho esperado e nada é alterado.
Para complementar esse raciocínio, existe um recurso útil no .replace() que permite limitar a quantidade de substituições realizadas. Basta passar um terceiro argumento com o número máximo de trocas desejadas. Veja o exemplo abaixo:
texto = "GEOVANA ALESSANDRA DIAS SANYOS"
texto = texto.replace("Y", "T", 1)
print(texto)
Nesse caso, apenas a primeira ocorrência de "Y" é substituída por "T", preservando as demais letras iguais que possam aparecer no restante do texto. Esse cuidado é essencial quando trabalhamos com strings mais complexas no dia a dia.
Você chegou a testar esse terceiro parâmetro do .replace() durante o exercício, ou foi a primeira vez que teve contato com essa possibilidade?
 Conteúdo relacionado:
Conteúdo relacionado:
 Conte com o apoio da comunidade Alura na sua jornada. Abraços e bons estudos!
Conte com o apoio da comunidade Alura na sua jornada. Abraços e bons estudos!