
Abaixo, todo o código. Acho que minha "def transformando_dados_tabela(dados,nomes_colunas):" está errada, mas não sei o motivo.
Quando eu printei na tela o resultado, veja o que aconteceu:
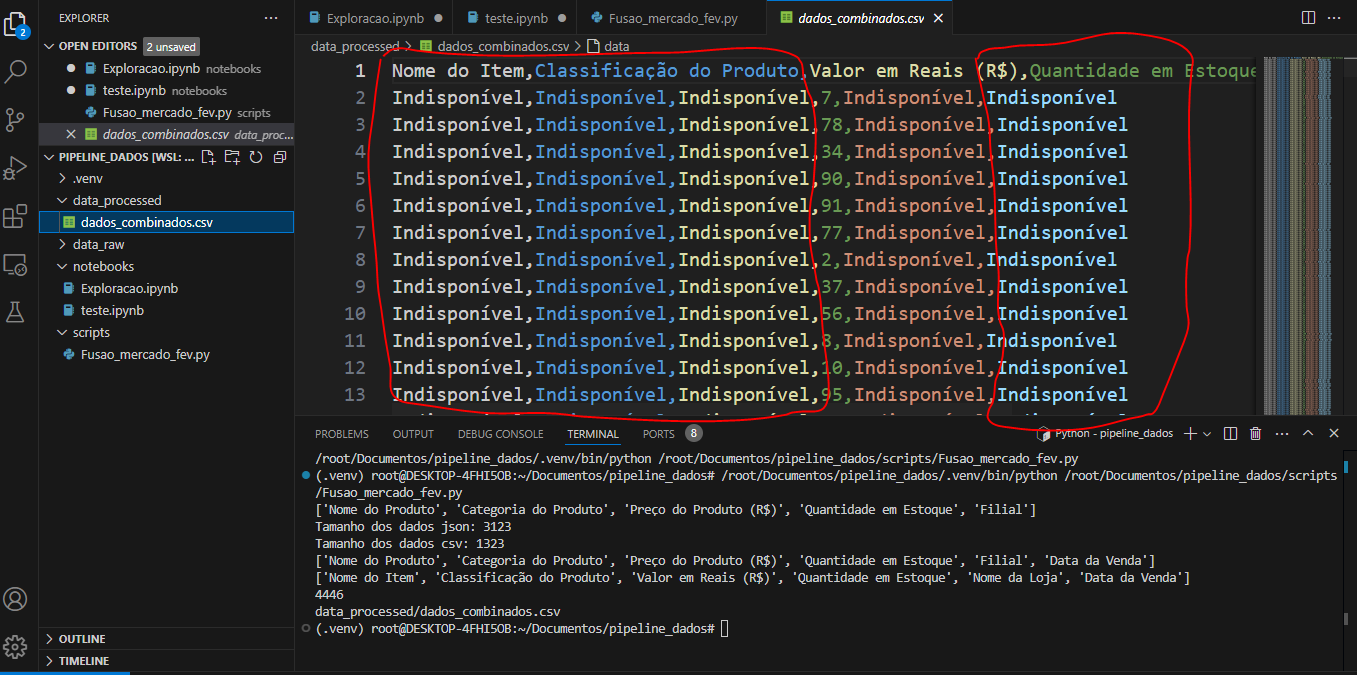 Tudo saiu como indisponível, menos o valor em reais. Está errado isso.
Tudo saiu como indisponível, menos o valor em reais. Está errado isso.
import json #Importo a biblioteca do json
import csv
#Início das funções que eu criei
def leitura_json(path_json):
dados_json=[]
with open(path_json,'r') as file: #Aqui, eu digo que a leitura é um arquivo e chamo ele de file.O 'r' é um comando de ler
dados_json=json.load(file) #declaro uma variável e digo para ela executar o file
return dados_json
def leitura_csv(path_csv):
dados_csv=[]
with open(path_csv,'r') as file:
spamreader=csv.DictReader(file, delimiter=',')
for row in spamreader:
dados_csv.append(row)
return dados_csv
def leitura_dados(path, tipo_arquivo):
dados = []
if tipo_arquivo == 'csv':
dados = leitura_csv(path)
elif tipo_arquivo == 'json':
dados = leitura_json(path)
return dados
def get_columns(dados):
return list(dados[-1].keys())
def rename_columns(dados, key_mapping):
new_dados_csv = []
for old_dict in dados:
dict_temp = {}
for old_key, value in old_dict.items():
dict_temp[key_mapping[old_key]] = value
new_dados_csv.append(dict_temp)
return new_dados_csv
def size_data(dados):
return len(dados)
def join(dadosA,dadosB):
combined_list=[]
combined_list.extend(dados_json)
combined_list.extend(dados_csv)
return combined_list
def transformando_dados_tabela(dados,nomes_colunas):
dados_combinados_tabela=[nomes_colunas]
for row in dados:
linha=[]
for coluna in nomes_colunas:
linha.append(row.get(coluna,'Indisponível'))
dados_combinados_tabela.append(linha)
return dados_combinados_tabela
def salvando_dados(dados, path):
with open(path, 'w') as file:
writer = csv.writer(file)
writer.writerows(dados)
#Fim das funções
path_json='data_raw/dados_empresaA.json' #indico o caminho do arquivo nas pastas
path_csv= 'data_raw/dados_empresaB.csv'
#Iniciando a leitura
dados_json = leitura_dados(path_json, 'json')
nome_colunas_json = get_columns(dados_json)
tamanho_dados_json=size_data(dados_json)
print(nome_colunas_json)
print(f"Tamanho dos dados json: {tamanho_dados_json}")
dados_csv = leitura_dados(path_csv, 'csv')
nome_colunas_csv = get_columns(dados_csv)
tamanho_dados_csv=size_data(dados_csv)
print(f"Tamanho dos dados csv: {tamanho_dados_csv}")
key_mapping = {'Nome do Item': 'Nome do Produto',
'Classificação do Produto': 'Categoria do Produto',
'Valor em Reais (R$)': 'Preço do Produto (R$)',
'Quantidade em Estoque': 'Quantidade em Estoque',
'Nome da Loja': 'Filial',
'Data da Venda': 'Data da Venda'}
key_mapping
#Transformação de dados
new_dados_csv = rename_columns(dados_csv, key_mapping)
colunas_new_dados_csv=get_columns(new_dados_csv)
print(colunas_new_dados_csv)
dados_fusao = join(dados_json,dados_csv)
nomes_colunas_fusao = get_columns(dados_fusao)
tamanho_dados_fusao = size_data(dados_fusao)
print(nomes_colunas_fusao)
print(tamanho_dados_fusao)
#Salvando dados
dados_fusao_tabela = transformando_dados_tabela(dados_fusao,nomes_colunas_fusao)
path_dados_combinados = 'data_processed/dados_combinados.csv'
salvando_dados(dados_fusao_tabela, path_dados_combinados)
print(path_dados_combinados)

