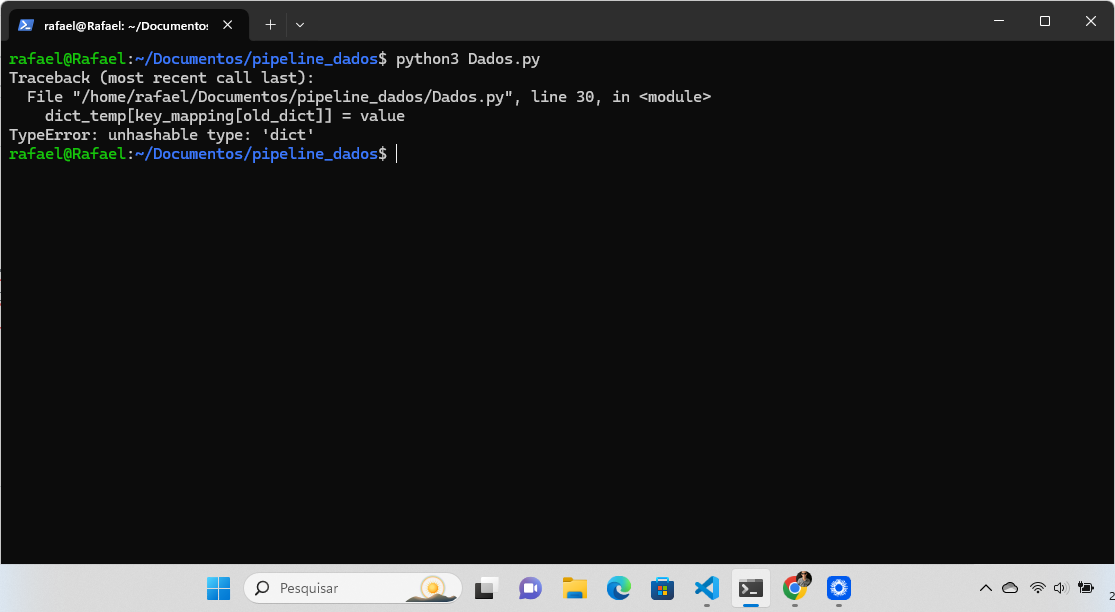
É como se não encontrasse o dicionário nesta linha. Segue código completo:
import csv import json dados_csv = [] path_csv = 'data_raw/dados_empresaB.csv' with open(path_csv, 'r') as file: spamreader = csv.DictReader(file, delimiter=',') for row in spamreader: dados_csv.append(row) dados_colunas_csv = dados_csv[0].keys()
path_json = 'data_raw/dados_empresaA.json' with open(path_json, 'r') as file: dados_json = json.load(file) nome_colunas_json = list(dados_json[0].keys())
key_mapping = {'Nome do Item': 'Nome do Produto', 'Classificação do Produto': 'Categoria do Produto', 'Valor em Reais (R$)': 'Preço do Produto (R$)', 'Quantidade em Estoque': 'Quantidade em Estoque', 'Nome da Loja': 'Filial', 'Data da Venda': 'Data da Venda'}
new_dados_csv = [] for old_dict in dados_csv: dict_temp = {} for old_key, value in old_dict.items(): dict_temp[key_mapping[old_dict]] = value new_dados_csv.append(dict_temp) print(new_dados_csv[0])