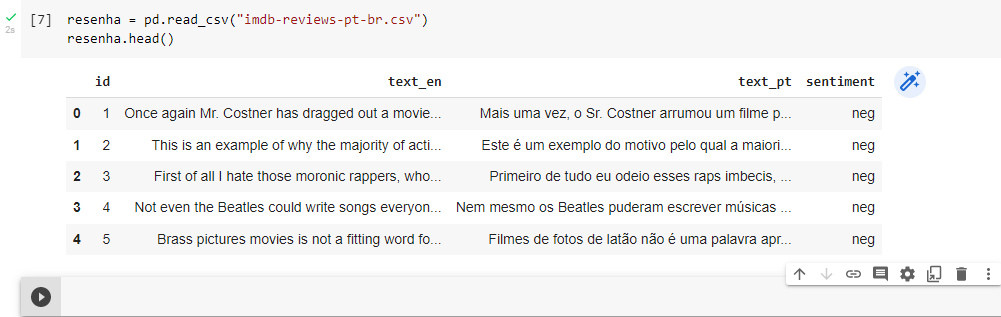
Já vi que tem várias pessoas com a mesma dúvida. O problema é que não tem resposta...
Não consigo ler o arquivo. Seria possível disponibilizar o arquivo CSV do professor ou nos explicar como fazer quando nos depararmos com problemas assim no dataset?
Outra coisa, por que não fazer uma aula de correção, já que tanta gente não conseguiu acessar o arquivo?
Para mim, aparece o seguinte erro:
---------------------------------------------------------------------------
ParserError Traceback (most recent call last)
<ipython-input-12-2020db379281> in <module>
----> 1 resenha = pd.read_csv("imdb-reviews-pt-br.csv")
8 frames
/usr/local/lib/python3.7/dist-packages/pandas/_libs/parsers.pyx in pandas._libs.parsers.raise_parser_error()
ParserError: Error tokenizing data. C error: **Expected 4 fields in line 808, saw 5**