Olá Diego! Tudo bem?
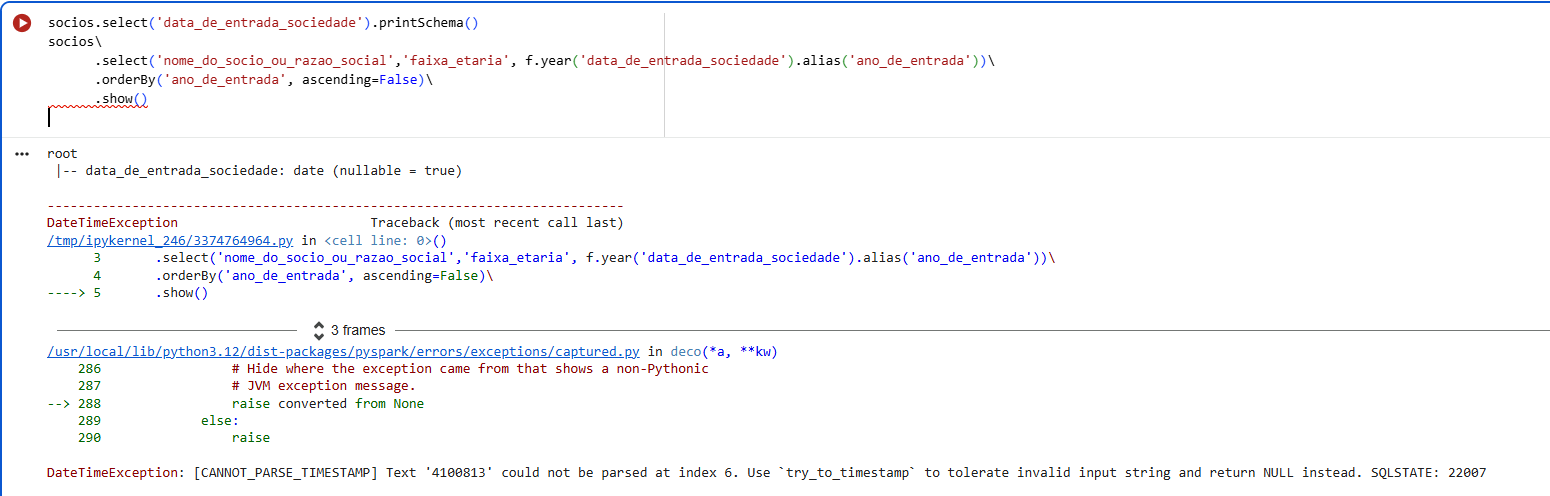
O erro DateTimeException: [CANNOT_PARSE_TIMESTAMP] ocorre porque o PySpark encontrou um valor na coluna data_de_entrada_sociedade que não está no formato de data esperado. No próprio erro aparece o exemplo '4100813', que não pode ser interpretado como uma data válida.
Primeiramente, recomendo revisar as células executadas anteriormente no notebook para verificar se houve alguma alteração ou transformação na coluna data_de_entrada_sociedade em etapas anteriores do código. Em alguns casos, alguma operação intermediária pode acabar modificando o formato dos dados e gerar esse tipo de inconsistência.
Caso queira comparar com uma execução de referência, você pode utilizar o notebook de exemplo abaixo. E caso queira executá-lo, lembre-se apenas de substituir pela sua própria chave, conforme descrito na atividade Para saber mais: Acessando o SparkUI no Colab.
Também pode ser útil reiniciar o ambiente do notebook para garantir que todas as células sejam executadas novamente na ordem correta:
- No menu do Google Colaboratory, clique em "Ambientes de execução"
- Selecione "Reiniciar sessão e executar tudo"
Você pode seguir o exemplo mostrado na imagem abaixo:

Peço que verifique esses pontos.
Se continuar com dificuldades, fique à vontade para compartilhar o seu notebook.
Abraços e bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!