
Olá, tudo bem?
Estive vendo a aula prática Pipeline para Dados Complexos Pratica #2. Na última parte da aula (minuto 17:08), é esperado que as duas perguntas diferentes retornem similaridade com documentos diferentes (uma associada ao PDF e outra associada aos registros via SQL). Na aula aparece que ambas retornam referência aos documentos relatorio_vendas.pdf, com documentos que em princípio não tem grande correlação com a pergunta em si. Adiciono a imagem para referência.
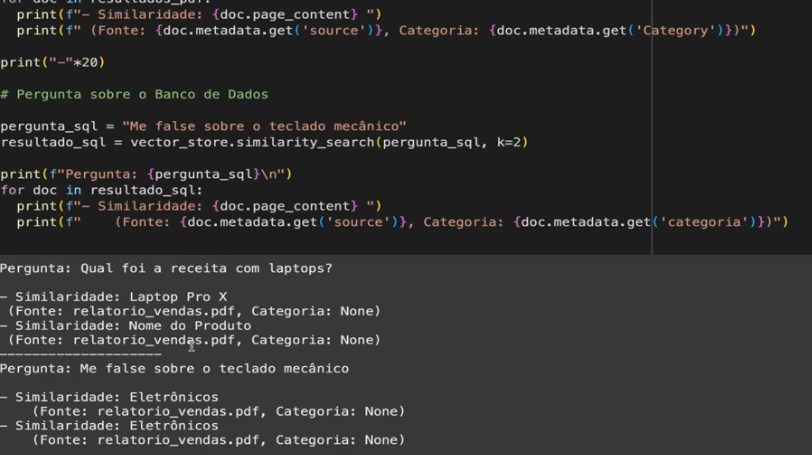
Qual seria a maneira ideal de ajustar os documentos para que o retrieval seja mais preciso para ambas as perguntas?

