Não entendi a resolução da questão. O que seria pontuação de código Unicode? E como ela estaria organizando os arrays n e p? Ela segue alguma lógica?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Não entendi a resolução da questão. O que seria pontuação de código Unicode? E como ela estaria organizando os arrays n e p? Ela segue alguma lógica?


Basicamente, todos os caracteres de uma fonte são mapeados dentro de uma tabela, onde cada caractere possui uma posição única dentro dela. E esta tabela varia conforme o tipo de codificação que utilizamos.
Para textos codificados em Unicode, um exemplo da tabela de mapeamento dos caracteres pode ser encontrada neste site. A imagem abaixo destaca o posicionamento dos caracteres alfanuméricos (sem acentuação).
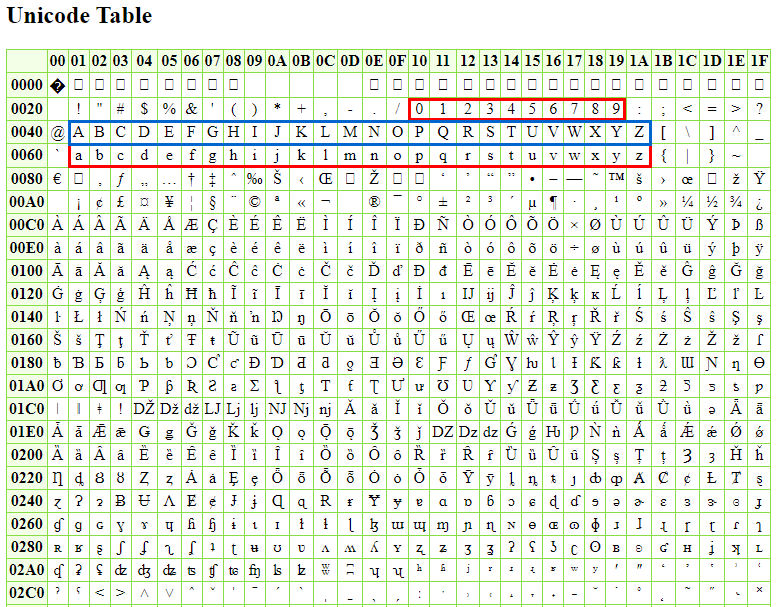
A posição de cada caractere pode ser calculada somando a linha com a coluna do mesmo (lembrando que os valores estão escritos são valores hexadecimais, base 16). Abaixo estão alguns exemplos:
Portanto, ao chamar a função sort, os valores da lista vão ser comparados como strings, sendo avaliados caractere a caractere, da esquerda para a direita.
const items = ['rafaela', 16.4, 'rafaelA', 4];
console.log(items.sort()); // [16.4, 4, 'rafaelA', 'rafaela']O 16.4 veio antes do 4, pois o caractere '1' tem um índice menor que o caractere '4'. E 'rafaelA' veio antes de 'rafaela', pois o índice do caractere 'A' é menor do que do caractere 'a'.