Olá, Marcelo. Como vai?
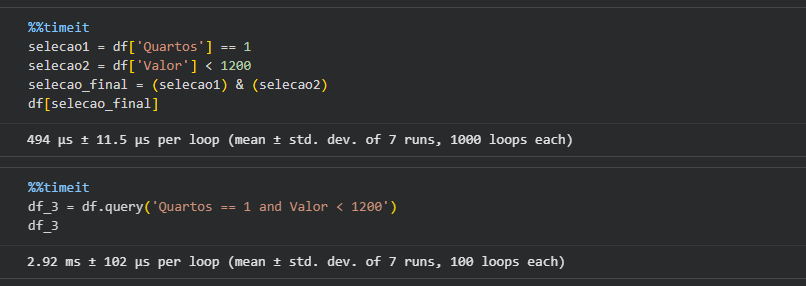
Sua dúvida é espetacular e o fato de você ter usado o comando mágico %%timeit para testar a performance por conta própria mostra que você tem o DNA de um verdadeiro Cientista de Dados. Parabéns pela postura investigativa!
A sua constatação está perfeitamente correta: para DataFrames pequenos e médios, a filtragem tradicional por máscaras booleanas (a primeira forma) é significativamente mais rápida que o método .query().
Vamos entender os motivos técnicos por trás dessa diferença de tempo, como o comportamento muda quando escalamos para volumes massivos de dados (Big Data) e os impactos na memória.
Por que o .query() é mais lento em datasets pequenos?
A elegância do .query('Quartos == 1 and Valor < 1200') tem um preço de processamento oculto. Quando você executa esse método, o Pandas não roda o filtro imediatamente; ele precisa realizar três etapas antes:
- Interpretação da String: O Pandas precisa ler a String que você digitou e traduzi-la em uma expressão lógica válida.
- Compilação: Ele utiliza uma biblioteca interna chamada
numexpr (ou o próprio interpretador Python) para compilar essa string em código de máquina. - Avaliação: Aí sim, ele aplica o filtro nas colunas.
Toda essa etapa de parsing e compilação gera um custo fixo de processamento (overhead). Na filtragem tradicional (df[selecao_final]), você está conversando diretamente com os arrays do NumPy em baixo nível. Não há tradução de texto; a operação matemática vetorial acontece de forma instantânea na memória.
O jogo vira com datasets gigantescos? (Performance vs Memória)
A sua intuição sobre o tamanho do dataset e o consumo de memória foi cirúrgica. Quando saímos de milhares de linhas e vamos para milhões de linhas, o comportamento muda por conta do motor de execução numexpr que o .query() usa por baixo dos panos.
1. Consumo de Memória
Na filtragem tradicional, quando você faz selecao1 = df['Quartos'] == 1, o Pandas cria um novo array booleano intermediário na memória (uma série de True e False). Em datasets massivos, criar essas variáveis intermediárias (selecao1, selecao2, selecao_final) pode estourar a memória RAM da sua máquina (Out of Memory Error).
O .query(), por utilizar o numexpr, consegue avaliar a expressão inteira de uma vez e otimizar a criação desses blocos temporários diretamente nos caches do processador, gastando muito menos memória RAM.
2. Performance em Big Data
À medida que o tamanho do DataFrame cresce, o tempo gasto para processar as linhas supera o custo fixo de interpretar a String do .query().
Como o numexpr é capaz de realizar computação paralela multithread (dividindo o processamento entre os núcleos da sua CPU), em datasets muito grandes o .query() passa a ser tão rápido ou até mais rápido que a máscara booleana tradicional.
Resumo dos Critérios de Escolha
Para resumir e te dar uma diretriz prática no dia a dia dos seus projetos:
| Critério | Máscara Tradicional (df[...]) | Método .query() |
|---|
| Datasets Pequenos/Médios | Muito mais rápida (Sem overhead de interpretação) | Mais lenta devido ao parse da string. |
| Datasets Gigantes (Milhões de linhas) | Alto consumo de memória por criar arrays intermediários. | Otimiza a memória e aproveita paralelismo. |
| Legibilidade | Pode ficar confusa com muitos operadores (&, ` | , ~`). |
| Uso em Loops / Funções | Ideal. É direta e fácil de passar variáveis nativas. | Exige o uso do caractere @ para ler variáveis de fora (ex: @limite). |
Sua análise foi cirúrgica e com certeza esse benchmark que você trouxe vai clarear a mente de muitos alunos que ficam na dúvida entre qual sintaxe escolher. Continue com essa mentalidade analítica!
Espero que possa ter lhe ajudado!