oi pessoal, tudo bem?
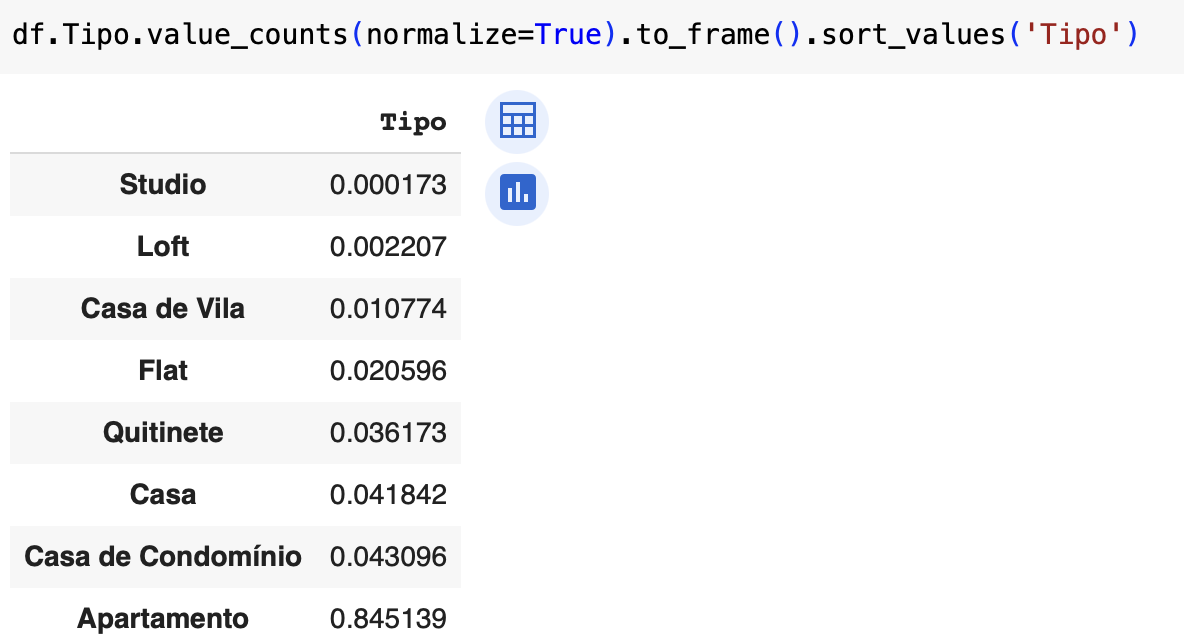
Fiquei com uma dúvida que pode ser meio besta, ou algo que não to enxergando no momento... mas como estamos reduzindo dados, nao era para diminuir o número de linhas? Inicialmente tinhamos uma tabela de 32 mil linhas x 9 colunas. Agora depois dessa aula fomos avançando até chegar somente apartamento de linha, que representa 80 e poucos porcento. Minha dúvida é: não era para ter os '80 e poucos porcento' de linhas no caso? No colab ele exibe com reticências e mostra até 32 mil linhas e pouco. Não sei se ficou claro. Embaixo do dataframe ele diz: '19532 rows × 9 columns' mas na exibição está 32 mil.
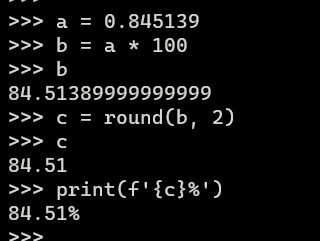
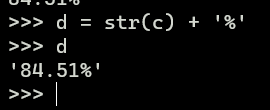
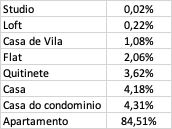
Aproveitando o tópico, não sei se será abordado mais para frente, mas como eu faço para quando exibir % deixar os valores com dezena (o dataframe só com os % ou no caso do gráfico também), é possível ? Tipo, apartamento tem 0.845139, da pra deixar 84.5139% ou até 84.51%?
Obrigado desde já.