
Olá, fiz o código durante a aula e apresentou o seguinte erro:
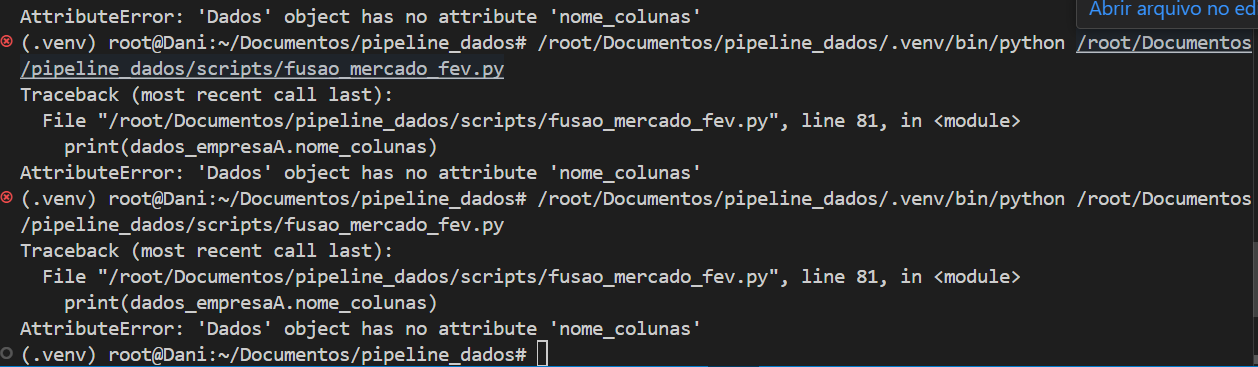
Verifiquei o código e os métodos da classe, mas não consegui localizar a divergência, poderiam me ajudar?
fusao_mercado_fev.py:
import json
import csv
import sys
sys.path.append ('scripts')
from processamento_dados import Dados
def leitura_json(path_json):
dados_json = []
with open(path_json, 'r') as file:
dados_json = json.load(file)
return dados_json
def leitura_csv(path_csv):
dados_csv = []
with open(path_csv, 'r') as file:
spamreader = csv.DictReader(file, delimiter=',') #DictReader trás os dados em formato de Dicionário, o comando Reader mantinha o formato list
for row in spamreader:
dados_csv.append(row)
return dados_csv
def leitura_dados(path, tipo_arquivo):
dados = []
if tipo_arquivo == 'csv':
dados = leitura_csv(path)
elif tipo_arquivo == 'json':
dados = leitura_json(path)
return dados
def get_comlumns(dados):
return list (dados[-1].keys())
def rename_columns(dados, key_mapping):
new_dados_csv = []
for old_dict in dados:
dict_temp = {}
for old_key, value in old_dict.items():
dict_temp[key_mapping[old_key]] = value
new_dados_csv.append(dict_temp)
return new_dados_csv
def size_data(dados):
return len(dados)
def join(dadosA, dadosB):
combined_list = []
combined_list.extend(dadosA)
combined_list.extend(dadosB)
return combined_list
def transformando_dados_tabela(dados, nomes_colunas):
dados_combinados_tabela = [nomes_colunas]
for row in dados:
linha = []
for coluna in nomes_colunas:
linha.append(row.get(coluna, 'Indisponível'))
dados_combinados_tabela.append(linha)
return dados_combinados_tabela
def salvando_dados(dados, path):
with open(path, 'w') as file:
writer = csv.writer(file)
writer.writerows(dados)
path_json = 'data_raw/dados_empresaA.json'
path_csv = 'data_raw/dados_empresaB.csv'
#Extract
dados_empresaA = Dados(path_json, 'json')
print(dados_empresaA.nome_colunas)
dados_empresaB = Dados(path_csv, 'csv')
print(dados_empresaB.nome_colunas)
processamento_dados.py:
import json
import csv
class Dados:
def __init__(self, path, tipo_dados):
self.path = path
self.tipo_dados = tipo_dados
self.dados = self.leitura_dados()
self.nome_colunas = self.get_comlumns()
def leitura_json(self):
dados_json = []
with open(self.path, 'r') as file:
dados_json = json.load(file)
return dados_json
def leitura_csv(self):
dados_csv = []
with open(self.path, 'r') as file:
spamreader = csv.DictReader(file, delimiter=',')
for row in spamreader:
dados_csv.append(row)
return dados_csv
def leitura_dados(self):
dados = []
if self.tipo_dados == 'csv':
dados = self.leitura_csv()
elif self.tipo_dados == 'json':
dados = self.leitura_json()
return dados
def get_comlumns(self):
return list (self.dados[-1].keys())

