Oi Victor! Tudo bem com você? Espero que sim!
O curso que você assistiu já está há um tempinho na plataforma e alguns métodos que foram utilizados antes no código podem ter sido atualizados nesse meio tempo e alterado o resultado final. Afirmo isso pois ao atualizar algumas bibliotecas, como a Pandas e Numpy, e rodar o código da aula novamente em minha máquina, foram mostrados resultados diferentes dos que obtive na primeira vez que realizei o curso. Isso é completamente normal e pode acontecer ao realizar qualquer curso da plataforma, então você não precisa se preocupar tanto com valores diferentes, o seu código não está incorreto ;-)
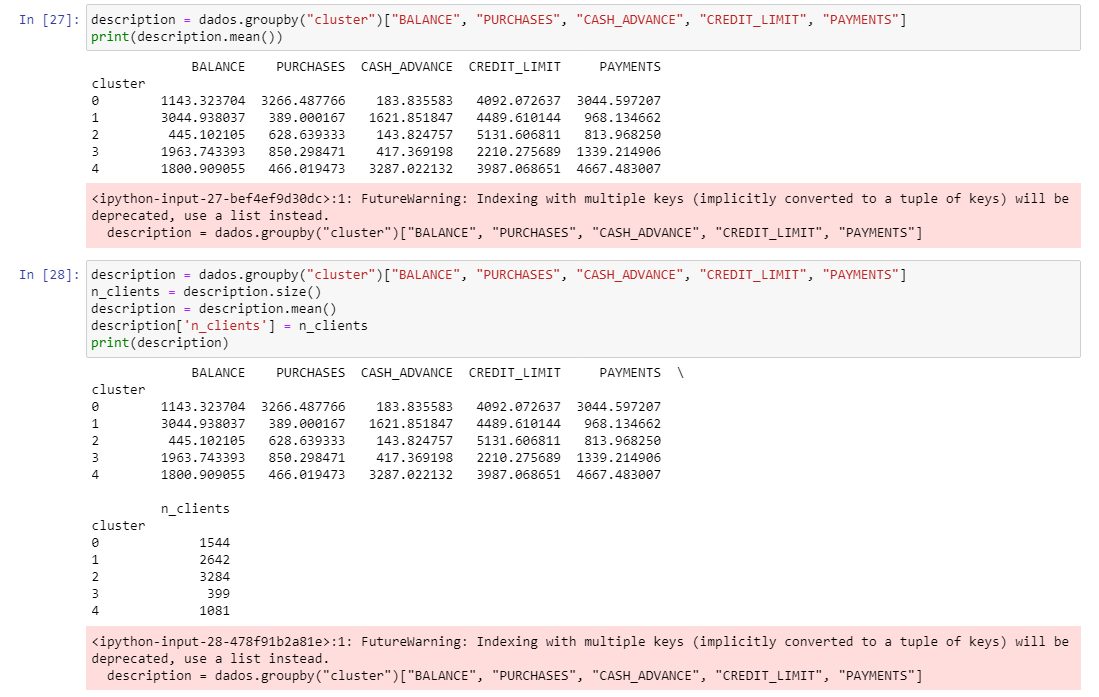
O FutureWarning surge pois a seleção de múltiplas colunas após utilizar o groupby não será mais permitida pelo Pandas desta forma após sua atualização. Quando vamos selecionar múltiplas colunas de um DataFrame devemos colocar os nomes das colunas entre duplos colchetes [[ ]] para que a seleção seja validada corretamente, mas em versões anteriores do Pandas a estrutura com apenas um colchete era suportada em groupby. Então para remover esse erro, basta apenas colocar mais um colchetes na seleção das colunas em groupby:
description = df.groupby('cluster')[['BALANCE', 'PURCHASES','CASH_ADVANCE','CREDIT_LIMIT','PAYMENTS']]
Por fim, a última coluna separada na saída da célula aconteceu porque foi utilizado o comando print() que, por padrão, quebra a linha do texto quando este é muito grande e pode ultrapassar o limite de espaço disponível para apresentação da saída. Para solucionar isso, você pode remover o comando print() e deixar apenas o nome da variável na última linha da célula de código que o compilador irá formatar o DataFrame em formato de tabela para você:
description = dados.groupby('cluster')[['BALANCE', 'PURCHASES','CASH_ADVANCE','CREDIT_LIMIT','PAYMENTS']]
n_clients = description.size()
description = description.mean()
description['n_clients'] = n_clients
description
Eu espero ter te ajudado! Se surgir outra dúvida estarei à disposição.
Bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!