Oi Lyse! Tudo bem com você?
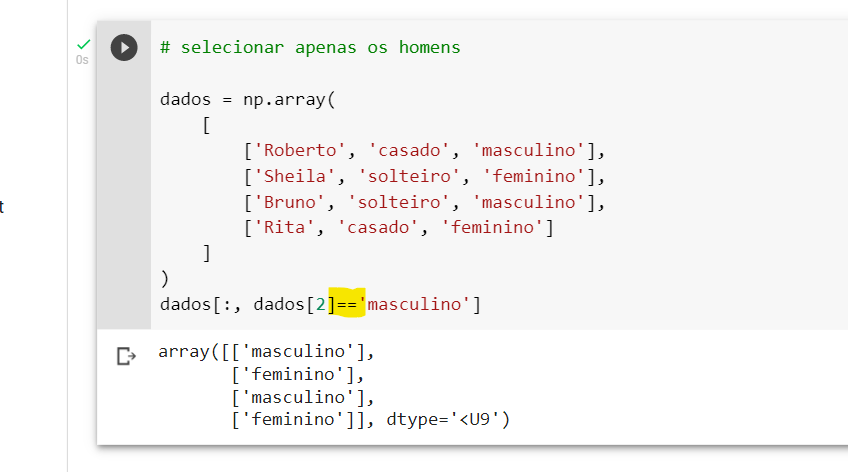
O == fez a comparação, mas não a que você queria que ele fizesse :(. Note que, você utilizou dados[2]=='masculino', isso fez com que apenas na linha 2 do seu array fossem verificadas quais dessas palavras é 'masculino', você pode ter uma melhor visualização disso verificando o resultado dessa comparação:
d = dados[2] == 'masculino'
d
#resultado:
array([False, False, True])
Esse array no final do código acima corresponde a análise feita com os elementos da linha 2, ou seja ['Bruno', 'solteiro', 'masculino'], como apenas o último elemento dos 3 é a palavra 'masculino', o único True no array é o último elemento. Ao utilizar dados[:,dados[2] == 'masculino'] você está pedindo para o programa selecionar todas as linha cujo a coluna é tem o resultado True no array dados[2] == 'masculino, por isso, só saiu a ultima coluna no resultado desse fatiamento.
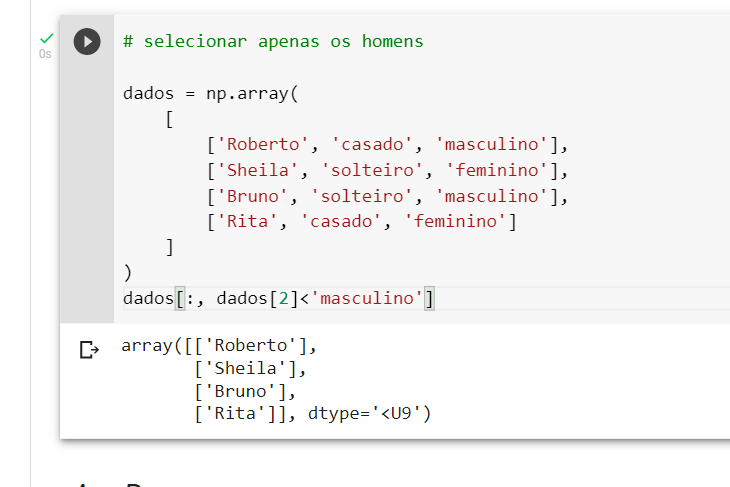
Já no segundo caso, sua ideia de comparar string está correta, por 'f' vir antes do 'm', o código vai dizer True onde começa com 'f', mas como foi implementada apenas para a linha 2 do array dados (['Bruno', 'solteiro', 'masculino']), a palavra 'Bruno' é a única que vem antes de 'masculino', resultando no array abaixo:
d = dados[2] < 'masculino'
d
#resultado
array([ True, False, False])
E pela mesma lógica explicada no primeiro caso, a sua saída foi apenas a primeira coluna do array.
A forma de você fazer isso funcionar não é complicada, você só vai precisar fazer a comparação com a coluna 2 ao invés da linha 2. Para isso você pode usar as ideias de fatiamento apresentadas nas aulas, selecionando todas as linhas e utilizando apenas a coluna 2 para a comparação do seguinte modo:
d = dados[:,2] == 'masculino'
d
#resultado
array([ True, False, True, False])
Como o array d é o resultado das comparações entre todas as linhas da última coluna de dados, ou seja ['masculino', 'feminino', 'masculino', 'feminino'], você pode coloca-lo normalmente na seleção das linhas do array dados:
d = dados[:,2] == 'masculino'
dados[d]
#resultado
array([['Roberto', 'casado', 'masculino'],
['Bruno', 'solteiro', 'masculino']], dtype='<U9')
Você ainda pode fatiar mais, deixando apenas as colunas com nome e o estado civil:
d = dados[:,2] == 'masculino'
dados[d,:2]
#resultado
array([['Roberto', 'casado'],
['Bruno', 'solteiro']], dtype='<U9')
Eu espero ter te ajudado! Se a dúvida persistir ou surgir outra dúvida estarei à disposição ;-)
Bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!