Olá, Carlos. Como vai?
Mais uma ótima entrega estrutural utilizando o encadeamento de múltiplas CTEs! O seu código demonstra que você compreendeu perfeitamente como modularizar consultas complexas para cruzar dados cadastrais, movimentações de contas e tabelas financeiras.
No entanto, analisando bem a regra de negócio proposta no enunciado ("Identificando clientes com múltiplas contas...") e cruzando com os operadores que você utilizou no script, identifiquei duas inconsistências importantes que estão alterando o resultado esperado da consulta, mesmo que o banco de dados tenha executado o código sem apresentar erros de sintaxe.
Vamos analisar onde a lógica divergiu da regra de negócio e como ajustá-la:
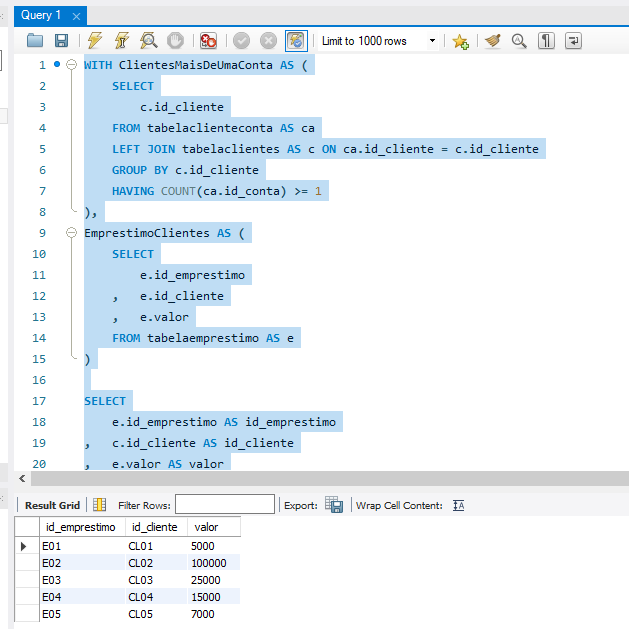
1. O Filtro do HAVING COUNT()
Na primeira CTE (ClientesMaisDeUmaConta), o objetivo é filtrar apenas as pessoas que possuem mais de uma conta corrente vinculada ao seu nome. No seu código, a condição foi escrita assim:
HAVING COUNT(ca.id_conta) >= 1
O problema lógico: Ao utilizar o operador maior ou igual a 1 (>= 1), a consulta está trazendo qualquer cliente que tenha pelo menos uma única conta cadastrada. Para atender ao critério de múltiplas contas, o contador precisa ser estritamente maior do que um (> 1) ou maior ou igual a dois (>= 2).
2. Ambiguidade de Aliases na Consulta Final
No seu SELECT de fechamento externo (linhas 17 a 20), você fez o mapeamento dos campos utilizando os aliases de tabela e. e c.:
SELECT
e.id_emprestimo AS id_emprestimo
, c.id_cliente AS id_cliente
, e.valor AS valor
FROM ClientesMaisDeUmaConta AS c
LEFT JOIN EmprestimoClientes AS e ON c.id_cliente = e.id_cliente
Se você reparar no início do seu código, a CTE EmprestimoClientes recebeu o alias e. Até aí, tudo bem. Porém, no FROM, você atribuiu o alias c para a CTE ClientesMaisDeUmaConta.
O problema de execução: Dentro da CTE ClientesMaisDeUmaConta, você selecionou apenas a coluna c.id_cliente da tabela original, mas omitiu o alias da subquery na saída. Quando a consulta externa tenta buscar e.id_emprestimo e e.valor, o banco de dados pode se perder ou retornar valores nulos dependendo de como o otimizador interpreta, pois as colunas da tabela interna tabelaemprestimo (usada na segunda CTE) precisam ser referenciadas a partir do nome da própria CTE que as envelopou (EmprestimoClientes).
Como Corrigir e Otimizar a Query
Para que o seu relatório exiba estritamente as informações corretas e performe como um script de nível de produção, podemos simplificar o processo. Como a tabela tabelaemprestimo já possui o ID de cada cliente, nós não precisamos de uma segunda CTE apenas para espelhar os dados brutos dela. Podemos fazer o JOIN final diretamente com a tabela física.
Veja a reestruturação ideal do seu código corrigindo os pontos lógicos:
WITH ClientesMaisDeUmaConta AS (
SELECT
ca.id_cliente
FROM tabelaclienteconta AS ca
GROUP BY ca.id_cliente
-- CORREÇÃO 1: Garante apenas clientes com MAIS de uma conta
HAVING COUNT(ca.id_conta) > 1
)
SELECT
e.id_emprestimo AS id_emprestimo,
cc.id_cliente AS id_cliente,
e.valor AS valor
FROM ClientesMaisDeUmaConta AS cc
-- CORREÇÃO 2: INNER JOIN direto na tabela de empréstimos, garantindo que
-- apenas os clientes com múltiplas contas E que possuam empréstimos apareçam
INNER JOIN tabelaemprestimo AS e ON cc.id_cliente = e.id_cliente;
Por que usar INNER JOIN no final?
O enunciado pede os empréstimos dos clientes com múltiplas contas. Se usarmos um LEFT JOIN a partir dos clientes, caso um cliente tenha 3 contas mas nenhuma dívida, ele aparecerá no relatório com os campos de empréstimo e valor como NULL. O INNER JOIN limpa o resultado, trazendo apenas quem cumpre os dois requisitos de negócio simultaneamente.
Fazer essa leitura crítica dos operadores e resultados (Result Grid) versus o que o cliente ou o negócio solicitou é o passo que eleva um Engenheiro de Dados do nível técnico para o nível estratégico. Excelente oportunidade de aprendizado com esse exercício!
Espero que possa ter lhe ajudado!