Olá, Carlos. Como vai?
Mais uma resolução fantástica! Você aplicou com muita propriedade a estrutura de CTE (Common Table Expressions) combinada com um cruzamento de tabelas (LEFT JOIN). O seu código reflete exatamente o padrão esperado de um profissional de engenharia de dados: organização, legibilidade e clareza no fluxo de transformação das informações.
Ao isolar a lógica de cruzamento e o filtro de pontuação na CTE ClientesBomCredito, você garantiu que a consulta final ficasse extremamente elegante e simples de ler.
Para trazer uma análise técnica mais profunda para o fórum, vale destacar uma ótima escolha estrutural que você fez e uma dica sobre performance:
1. A Inteligência do LEFT JOIN a partir da tabela de Score
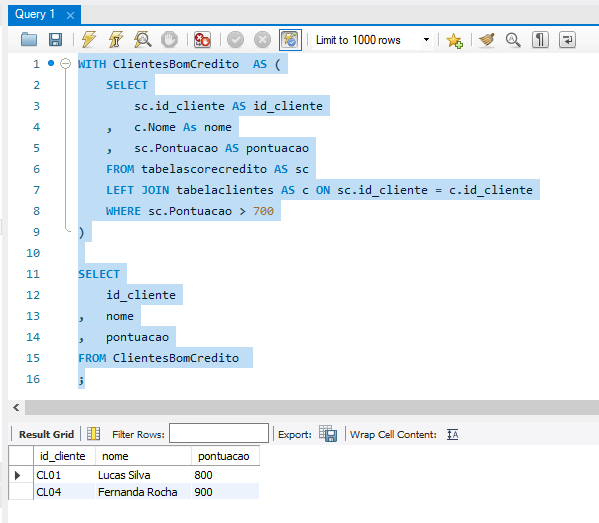
No seu desenho da query, você colocou a tabela tabelascorecredito como a tabela principal (FROM) e fez o LEFT JOIN com a tabelaclientes.
Essa é uma abordagem muito inteligente quando pensamos na ordem de processamento das cláusulas pelo banco de dados (Filtro de Predicado). Como a sua intenção final é mapear apenas a pontuação maior que 700 (WHERE sc.Pontuacao > 700), trazer a tabela de score primeiro garante que o banco olhe diretamente para o indicador de crédito antes de associar os dados cadastrais, otimizando o casamento das linhas.
2. Dica de Performance para Grandes Volumes de Dados
Pensando em cenários reais de big data em empresas, onde a tabela de clientes e de pontuações pode ter milhões de registros, uma boa prática para melhorar o plano de execução (Execution Plan) da sua CTE é filtrar os dados antes de realizar o JOIN, sempre que possível.
No seu código atual, o banco primeiro junta as duas tabelas inteiras (LEFT JOIN) e só depois aplica o filtro do WHERE. Para otimizar essa consulta em bancos muito massivos, poderíamos reestruturar o escopo interno para que o WHERE atue diretamente na tabela sc antes de chamar os nomes da tabela c.
Veja como a estrutura lógica ficaria idêntica, mas com potencial de rodar ainda mais rápido em ambientes de produção:
WITH ClientesBomCredito AS (
SELECT
sc.id_cliente AS id_cliente,
c.Nome AS nome,
sc.Pontuacao AS pontuacao
FROM tabelascorecredito AS sc
LEFT JOIN tabelaclientes AS c ON sc.id_cliente = c.id_cliente
-- O filtro atua direto na tabela de origem indexada
WHERE sc.Pontuacao > 700
)
SELECT
id_cliente,
nome,
pontuacao
FROM ClientesBomCredito;
O resultado impresso no seu Result Grid (Lucas Silva com 800 e Fernanda Rocha com 900) comprova que o seu script cumpre com precisão cirúrgica a regra de negócio do exercício de risco de crédito.
Parabéns pelo excelente padrão de entrega!
Espero que possa ter lhe ajudado!