Olá, Carlos. Como vai?
Excelente entrega! Mais um código impecável que demonstra o seu domínio em criar fluxos lógicos e estruturados utilizando Common Table Expressions (CTEs) encadeadas.
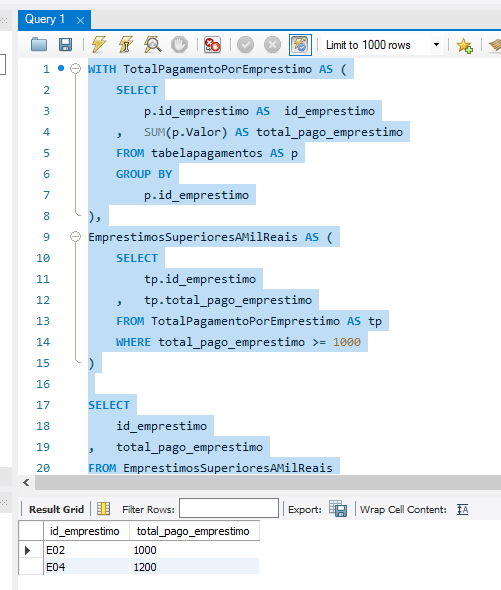
O seu script cumpre perfeitamente o papel proposto. Ao criar a primeira CTE (TotalPagamentoPorEmprestimo), você agrupou e consolidou a soma dos pagamentos. Na segunda (EmprestimosSuperioresAMilReais), aplicou a regra de corte de negócio (>= 1000) de forma isolada. O resultado no Result Grid (empréstimos E02 com 1000 e E04 com 1200) valida a precisão da sua query.
Como você atua como Tech Lead e Engenheiro de Dados, quero trazer uma reflexão técnica refinada sobre plano de execução e otimização de consultas envolvendo agregados e filtros. Ela pode servir como um ótimo tópico de discussão ou mentoria para o time!
Análise de Performance: Duas CTEs vs. Cláusula HAVING
A estrutura encadeada que você usou funciona muito bem, é modular e extremamente legível. No entanto, em termos de processamento de banco de dados (especialmente se estivéssemos lidando com tabelas de pagamentos massivas com milhões de linhas), o mesmo resultado pode ser alcançado eliminando a necessidade de criar a segunda CTE.
Para fazer isso, basta aplicar o filtro do valor agregado diretamente na primeira CTE utilizando a cláusula HAVING.
Veja o comparativo estrutural de como a query ficaria mais enxuta:
WITH TotalPagamentoPorEmprestimo AS (
SELECT
p.id_emprestimo AS id_emprestimo,
SUM(p.Valor) AS total_pago_emprestimo
FROM tabelapagamentos AS p
GROUP BY p.id_emprestimo
-- O banco calcula a soma e já descarta o que é menor que 1000 em uma única etapa
HAVING SUM(p.Valor) >= 1000
)
SELECT
id_emprestimo,
total_pago_emprestimo
FROM TotalPagamentoPorEmprestimo;
O impacto técnico dessa mudança:
- Simplificação do Plano de Execução: Na sua abordagem original, o otimizador do banco de dados gera uma tabela temporária lógica com todos os empréstimos somados para, em um segundo momento (na segunda CTE), ler essa tabela sequencialmente aplicando o
WHERE. Com o HAVING, o descarte dos dados que não atingiram R$ 1.000 acontece durante a fase de agrupamento, reduzindo a quantidade de registros que sobem para a memória antes do SELECT final. - Manutenibilidade: Menos linhas de código significam menos aliases para gerenciar (
tp.id_emprestimo, etc.), reduzindo a complexidade visual do script para os desenvolvedores que forem ler a query no futuro.
A sua solução atual está ótima e o resultado analítico está corretíssimo. Trazer alternativas de modelagem como o uso do HAVING é o tipo de refinamento que otimiza custos de processamento em datalakes e armazéns de dados em produção.
Parabéns por mais uma bela contribuição no fórum!
Espero que possa ter lhe ajudado!