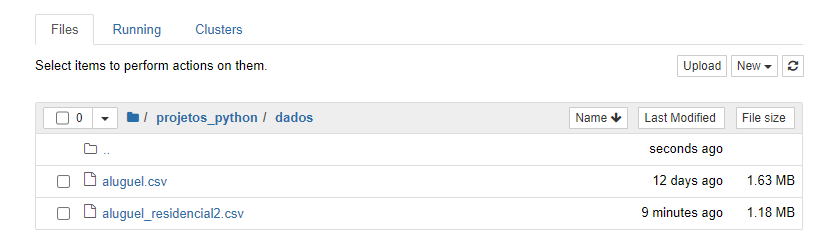
Após fechar o Jupiter e abrir novamente, não consigo mais fazer a leitura dos arquivos csv com o Pandas. Recebo um: FileNotFoundError: [Errno 2] No such file or directory: 'dados/alguel.csv'
Já tentei subir os arquivos novamente, renomeá-los e colocar o nome do diretório completinho.. nada parece resolver. O que estou fazendo errado?
Erro completo:
1. import pandas as pd
2. dados = pd.read_csv('projetos_python/dados/alguel.csv')
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Input In [4], in <cell line: 1>()
----> 1 dados = pd.read_csv('projetos_python/dados/alguel.csv')
File ~\anaconda3\lib\site-packages\pandas\util\_decorators.py:311, in deprecate_nonkeyword_arguments.<locals>.decorate.<locals>.wrapper(*args, **kwargs)
305 if len(args) > num_allow_args:
306 warnings.warn(
307 msg.format(arguments=arguments),
308 FutureWarning,
309 stacklevel=stacklevel,
310 )
--> 311 return func(*args, **kwargs)
File ~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py:680, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, error_bad_lines, warn_bad_lines, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options)
665 kwds_defaults = _refine_defaults_read(
666 dialect,
667 delimiter,
(...)
676 defaults={"delimiter": ","},
677 )
678 kwds.update(kwds_defaults)
--> 680 return _read(filepath_or_buffer, kwds)
File ~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py:575, in _read(filepath_or_buffer, kwds)
572 _validate_names(kwds.get("names", None))
574 # Create the parser.
--> 575 parser = TextFileReader(filepath_or_buffer, **kwds)
577 if chunksize or iterator:
578 return parser
File ~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py:933, in TextFileReader.__init__(self, f, engine, **kwds)
930 self.options["has_index_names"] = kwds["has_index_names"]
932 self.handles: IOHandles | None = None
--> 933 self._engine = self._make_engine(f, self.engine)
File ~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py:1217, in TextFileReader._make_engine(self, f, engine)
1213 mode = "rb"
1214 # error: No overload variant of "get_handle" matches argument types
1215 # "Union[str, PathLike[str], ReadCsvBuffer[bytes], ReadCsvBuffer[str]]"
1216 # , "str", "bool", "Any", "Any", "Any", "Any", "Any"
-> 1217 self.handles = get_handle( # type: ignore[call-overload]
1218 f,
1219 mode,
1220 encoding=self.options.get("encoding", None),
1221 compression=self.options.get("compression", None),
1222 memory_map=self.options.get("memory_map", False),
1223 is_text=is_text,
1224 errors=self.options.get("encoding_errors", "strict"),
1225 storage_options=self.options.get("storage_options", None),
1226 )
1227 assert self.handles is not None
1228 f = self.handles.handle
File ~\anaconda3\lib\site-packages\pandas\io\common.py:789, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
784 elif isinstance(handle, str):
785 # Check whether the filename is to be opened in binary mode.
786 # Binary mode does not support 'encoding' and 'newline'.
787 if ioargs.encoding and "b" not in ioargs.mode:
788 # Encoding
--> 789 handle = open(
790 handle,
791 ioargs.mode,
792 encoding=ioargs.encoding,
793 errors=errors,
794 newline="",
795 )
796 else:
797 # Binary mode
798 handle = open(handle, ioargs.mode)
FileNotFoundError: [Errno 2] No such file or directory: 'projetos_python/dados/alguel.csv'