
Meu objetivo no curso foi entender um pouco da API do hugging face. Então, usei um modelo dentro da própria pipeline:
classificador = pipeline('sentiment-analysis', model='tabularisai/multilingual-sentiment-analysis')
Contudo, esse modelo tem mais categorias de resultados e é multilingual. Os resultados possíveis são Very Positive, Positive, Neutral, Negative e Very Negative. Então, adaptei o cálculo de resultados atribuindo um código a cada resultado possível: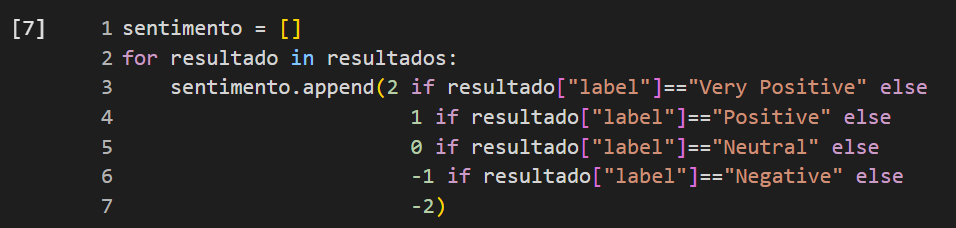
O agrupamento de resenhas por sentimentos resultou em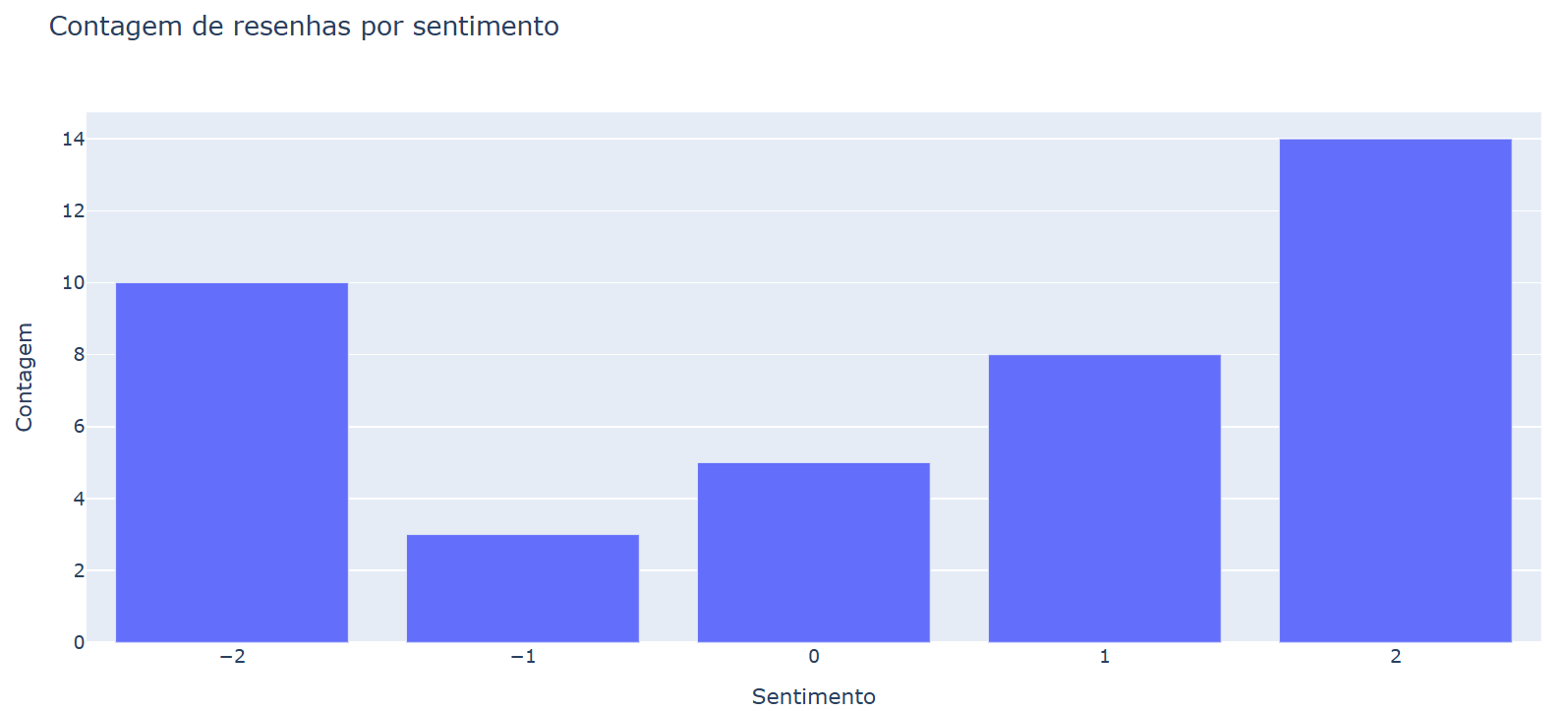
A função de núvem de palavras também foi adaptada: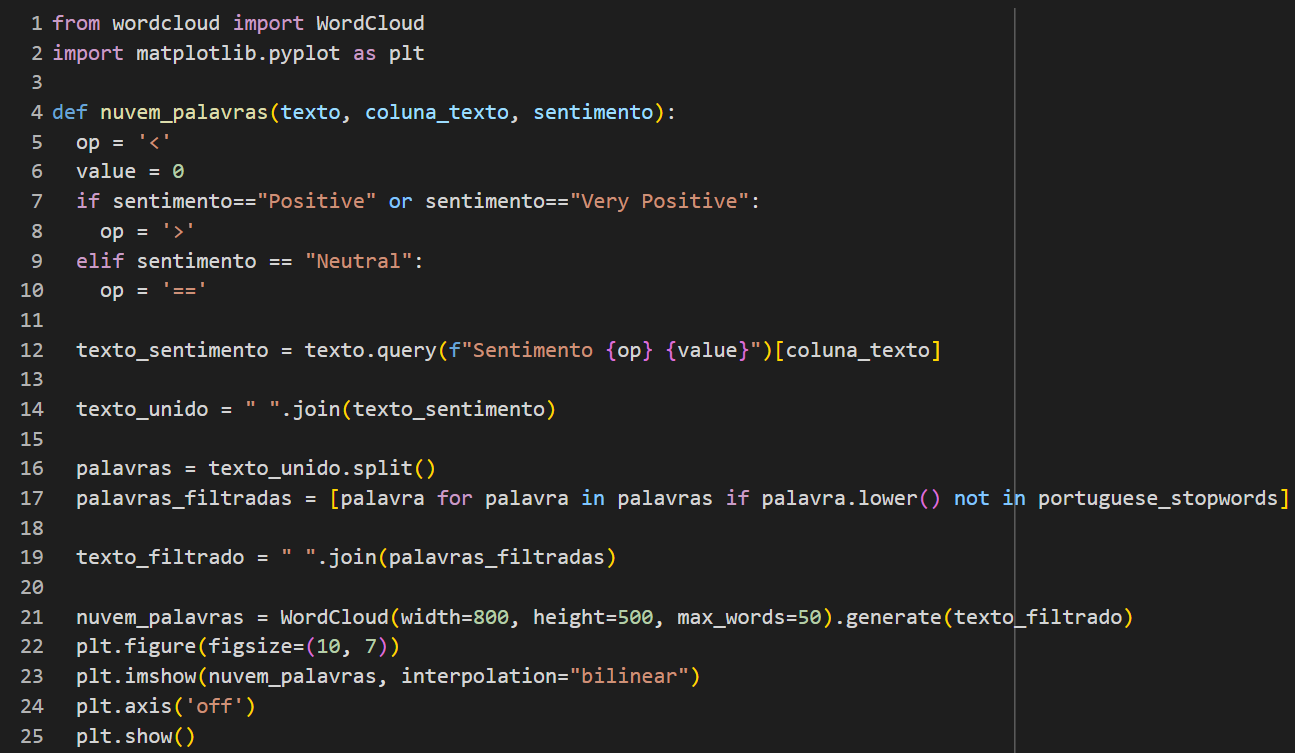
A núvem de palavras para resenhas positivas e muito positivas resultou em
Já para resenhas negativas e muito negativas, temos

