
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# Carregando o dataset Iris
iris = load_iris()
# Criando um DataFrame
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
print(df.head())
Neste primeiro momento, o dataset Iris foi carregado a partir da biblioteca sklearn.datasets e convertido em um DataFrame do Pandas, facilitando a visualização e a manipulação dos dados.
from sklearn.cluster import KMeans
# Selecionando apenas as features
X = iris.data
# Aplicando K-Means com 3 clusters
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Adicionando os clusters ao DataFrame
df['kmeans_cluster'] = kmeans_labels
print(df[['kmeans_cluster']].head())

Foi aplicado o algoritmo K-Means com 3 clusters, buscando identificar agrupamentos naturais entre as amostras do dataset. O número 3 foi utilizado por sabermos que o Iris possui três grupos principais de flores, o que também ajuda na comparação dos resultados.
from sklearn.cluster import AgglomerativeClustering
# Aplicando agrupamento hierárquico
hierarchical = AgglomerativeClustering(n_clusters=3)
hierarchical_labels = hierarchical.fit_predict(X)
# Adicionando os clusters ao DataFrame
df['hierarchical_cluster'] = hierarchical_labels
print(df[['hierarchical_cluster']].head())

Nesta etapa, foi utilizado o Hierarchical Clustering, por meio da abordagem aglomerativa. Esse método começa tratando cada ponto como um grupo isolado e vai unindo os mais próximos até formar os clusters finais.
from sklearn.decomposition import PCA
# Reduzindo para 2 dimensões
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# Criando DataFrame com os componentes principais
df_pca = pd.DataFrame(X_pca, columns=['PC1', 'PC2'])
df_pca['kmeans_cluster'] = kmeans_labels
df_pca['hierarchical_cluster'] = hierarchical_labels
df_pca['target'] = iris.target
print(df_pca.head())

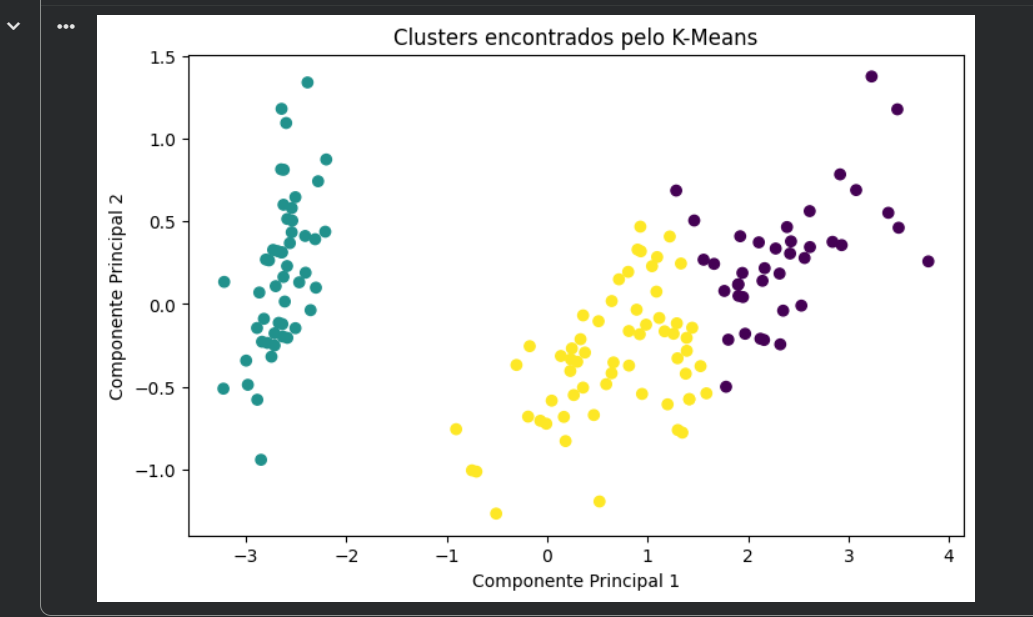
Aqui foi aplicado o PCA para reduzir as 4 variáveis originais do Iris para apenas 2 componentes principais. Isso permite visualizar os dados em duas dimensões, preservando a maior parte possível da variabilidade presente no conjunto original.
plt.figure(figsize=(8, 5))
plt.scatter(df_pca['PC1'], df_pca['PC2'], c=df_pca['kmeans_cluster'])
plt.title('Clusters encontrados pelo K-Means')
plt.xlabel('Componente Principal 1')
plt.ylabel('Componente Principal 2')
plt.show()
plt.figure(figsize=(8, 5))
plt.scatter(df_pca['PC1'], df_pca['PC2'], c=df_pca['hierarchical_cluster'])
plt.title('Clusters encontrados pelo Hierarchical Clustering')
plt.xlabel('Componente Principal 1')
plt.ylabel('Componente Principal 2')
plt.show()

Com os dados projetados em duas dimensões pelo PCA, foi possível visualizar os agrupamentos encontrados por cada algoritmo e observar como as amostras se organizam no espaço.
Com essa prática, foi possível observar como o aprendizado não supervisionado permite identificar padrões e agrupamentos naturais em um conjunto de dados, mesmo sem o uso de rótulos durante o treinamento. O K-Means e o Hierarchical Clustering mostraram maneiras diferentes de organizar os dados em grupos, enquanto o PCA ajudou a reduzir a dimensionalidade e tornar essa estrutura mais visível.
Dessa forma, a atividade demonstra como técnicas de agrupamento e redução de dimensionalidade podem ser utilizadas em conjunto para explorar melhor os dados, identificar relações entre amostras e apoiar análises mais claras e interpretáveis.
Eu pensei em colocar o código completo aqui, porém excedeu o limite de caracteres, porém é possível coletar o código bloco a bloco.
Respeitosamente.

