
Foi desenvolvido um classificador supervisionado utilizando o dataset Iris, disponível na biblioteca sklearn. Inicialmente, os dados foram carregados e convertidos para um DataFrame do Pandas para facilitar a exploração. Em seguida, foram separados os atributos e os rótulos, e os dados foram divididos em conjuntos de treino e teste.
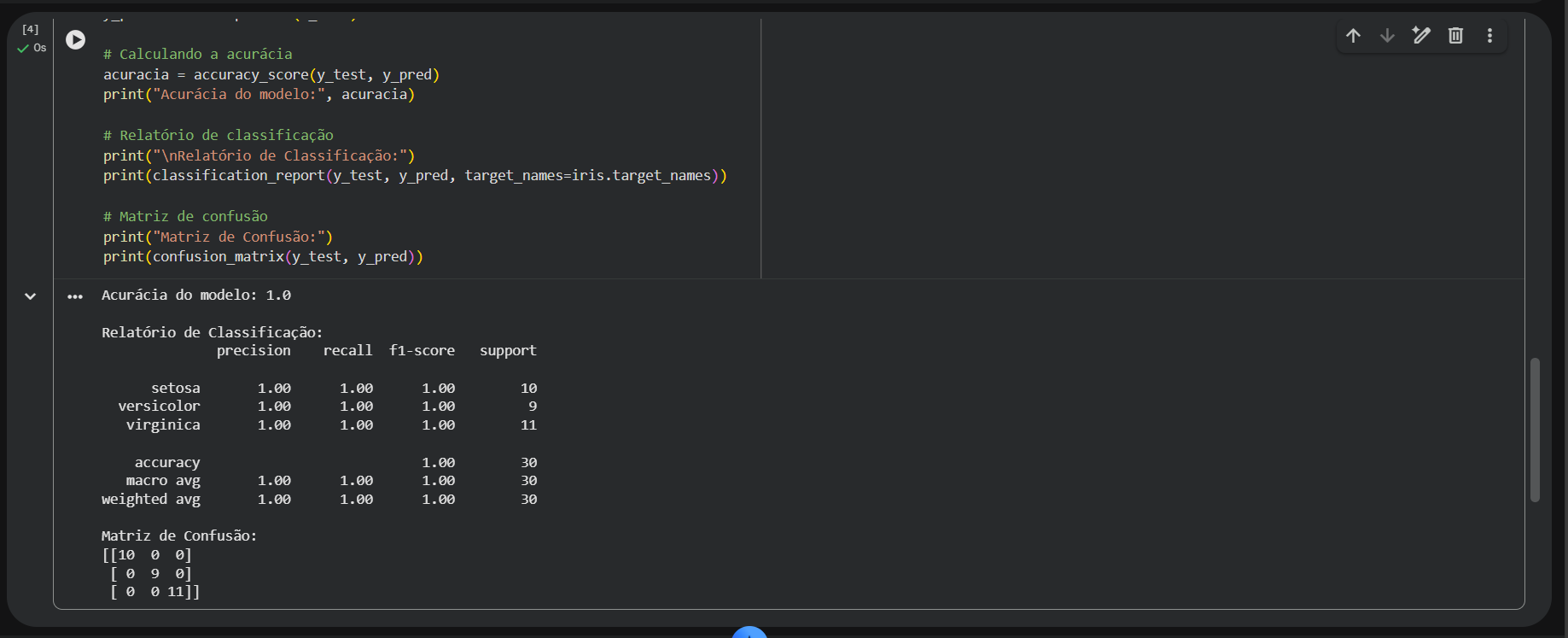
Para o treinamento, foi utilizado o algoritmo K-Nearest Neighbors (KNN), que classifica novas amostras com base nas amostras mais próximas. Após o treinamento, o modelo foi avaliado com base na acurácia, relatório de classificação e validação cruzada. Por fim, o sistema foi testado com novos exemplos, demonstrando sua capacidade de prever a espécie de flores com base nas medidas informadas.
Essa atividade demonstra, na prática, como funciona o aprendizado supervisionado, em que o modelo aprende por meio de dados rotulados e realiza previsões sobre novos dados.
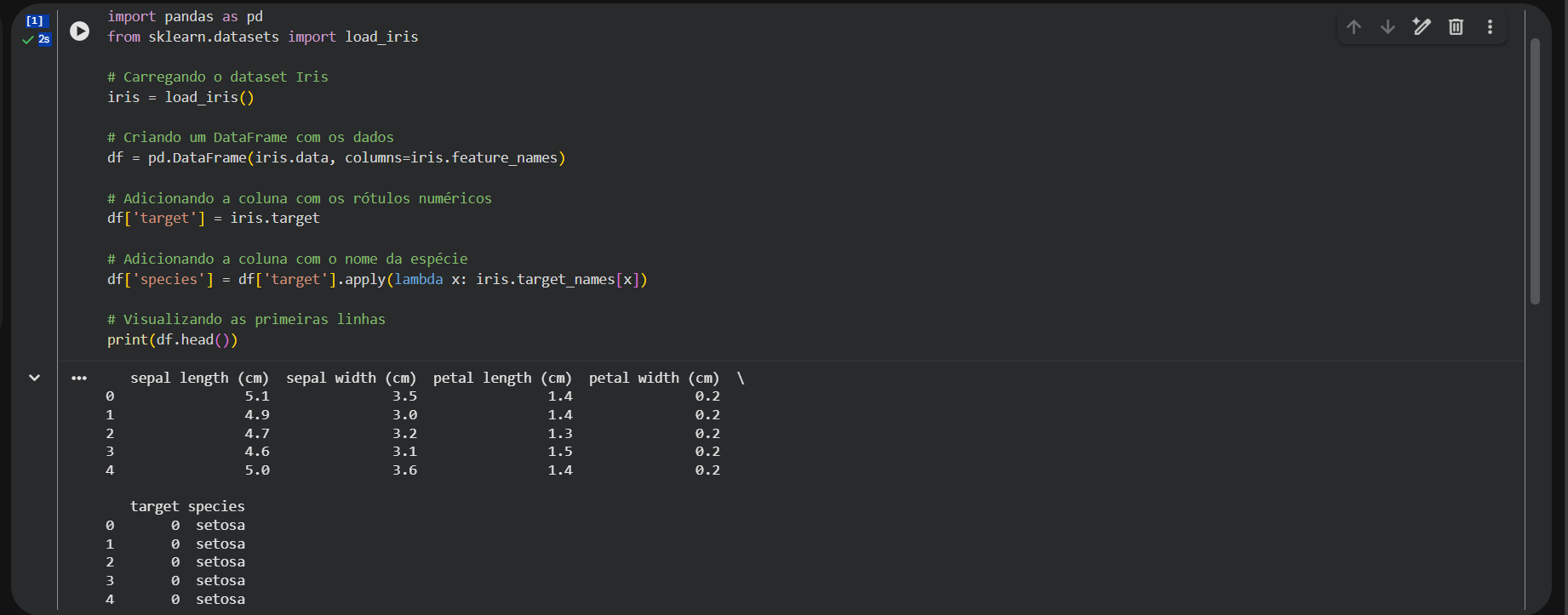
# Importando bibliotecas
import pandas as pd
from sklearn.datasets import load_iris
# Carregando o dataset Iris
iris = load_iris()
# Criando um DataFrame com os dados
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# Adicionando a coluna com os rótulos numéricos
df['target'] = iris.target
# Adicionando a coluna com o nome da espécie
df['species'] = df['target'].apply(lambda x: iris.target_names[x])
# Visualizando as primeiras linhas
print(df.head())
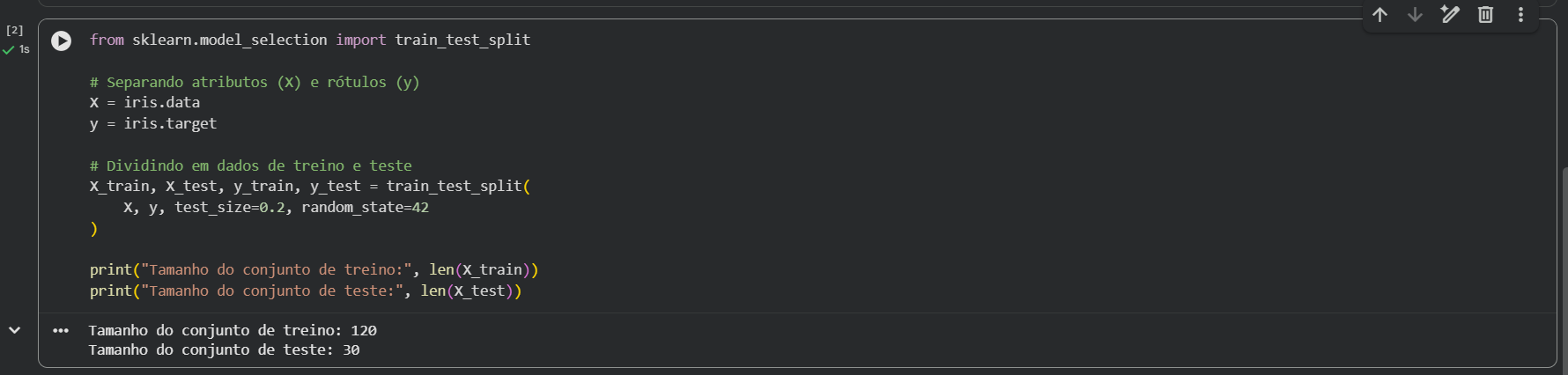
from sklearn.model_selection import train_test_split
# Separando atributos (X) e rótulos (y)
X = iris.data
y = iris.target
# Dividindo em dados de treino e teste
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print("Tamanho do conjunto de treino:", len(X_train))
print("Tamanho do conjunto de teste:", len(X_test))
from sklearn.neighbors import KNeighborsClassifier
# Criando o modelo
modelo = KNeighborsClassifier(n_neighbors=3)
# Treinando o modelo
modelo.fit(X_train, y_train)

from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# Fazendo previsões
y_pred = modelo.predict(X_test)
# Calculando a acurácia
acuracia = accuracy_score(y_test, y_pred)
print("Acurácia do modelo:", acuracia)
# Relatório de classificação
print("\nRelatório de Classificação:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# Matriz de confusão
print("Matriz de Confusão:")
print(confusion_matrix(y_test, y_pred))
from sklearn.model_selection import cross_val_score
# Validação cruzada com 5 partições
scores = cross_val_score(modelo, X, y, cv=5)
print("Acurácias em cada partição:", scores)
print("Acurácia média:", scores.mean())

# Exemplo de nova flor:
# [comprimento da sépala, largura da sépala, comprimento da pétala, largura da pétala]
nova_flor = [[5.1, 3.5, 1.4, 0.2]]
# Fazendo a previsão
previsao = modelo.predict(nova_flor)
# Exibindo o nome da espécie prevista
print("Espécie prevista:", iris.target_names[previsao[0]])

Caso deseje ver o código no colab.research me envia o email que lhe dou acesso professor.
Respeitosamente...

