
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
# Carregando um dataset de classificação
iris = load_iris()
X = iris.data
y = iris.target
# Separando treino e teste
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Definindo o modelo
modelo = DecisionTreeClassifier(random_state=42)
# Definindo os hiperparâmetros para teste
param_grid = {
'max_depth': [2, 3, 4, 5, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# Aplicando Grid Search
grid_search = GridSearchCV(
estimator=modelo,
param_grid=param_grid,
cv=5,
scoring='accuracy'
)
grid_search.fit(X_train, y_train)
# Melhor modelo encontrado
melhor_modelo = grid_search.best_estimator_
# Previsões
y_pred = melhor_modelo.predict(X_test)
print("Melhores hiperparâmetros encontrados:")
print(grid_search.best_params_)
print("\nAcurácia no conjunto de teste:")
print(accuracy_score(y_test, y_pred))
print("\nRelatório de classificação:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
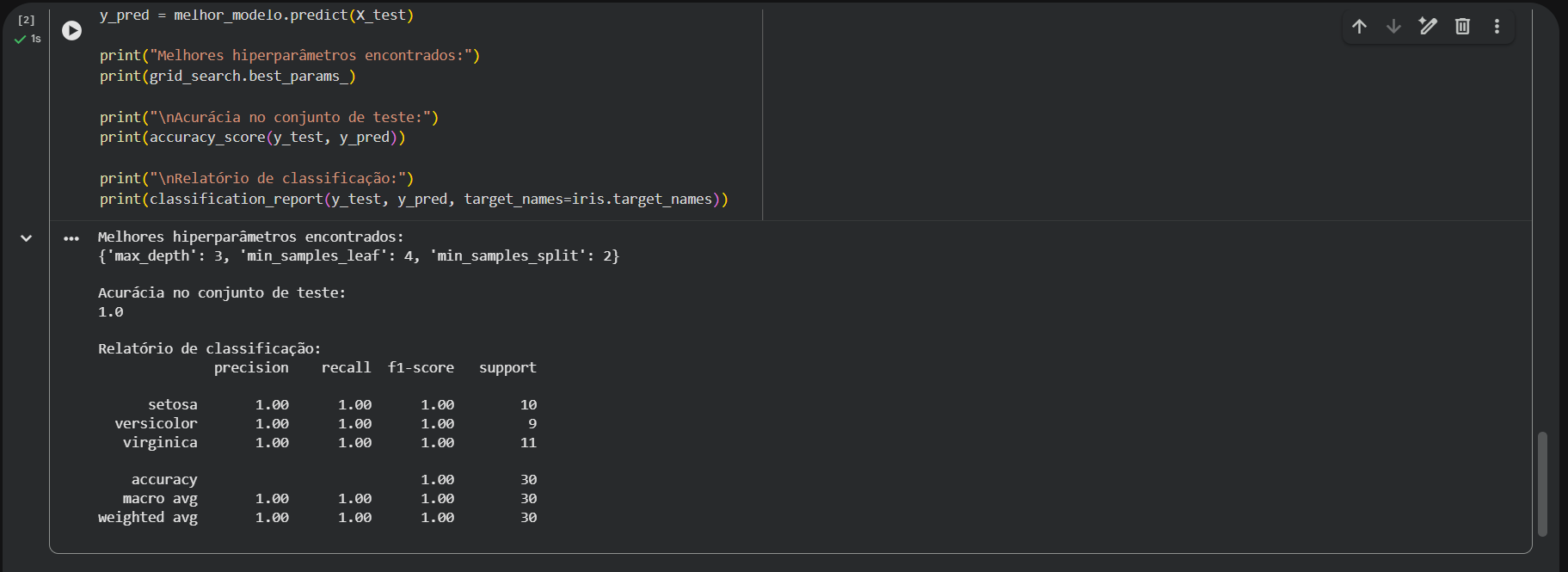
O que foi feito aqui?
Nesse primeiro momento, utilizamos o Grid Search para testar diferentes combinações de parâmetros da árvore de decisão, como profundidade máxima da árvore, número mínimo de amostras para divisão e número mínimo de amostras por folha. Ao final, o algoritmo retorna a combinação que apresentou o melhor desempenho.
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
import matplotlib.pyplot as plt
# Carregando dataset de diabetes
diabetes = load_diabetes()
X = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
y = diabetes.target
# Treinando modelo para analisar importância das variáveis
modelo_rf = RandomForestRegressor(random_state=42)
modelo_rf.fit(X, y)
# Importância das features
importancias = pd.Series(modelo_rf.feature_importances_, index=X.columns)
importancias = importancias.sort_values(ascending=False)
print("Importância das variáveis:")
print(importancias)
# Gráfico
plt.figure(figsize=(10, 6))
importancias.plot(kind='bar')
plt.title('Importância das Features na Previsão de Diabetes')
plt.ylabel('Importância')
plt.xlabel('Features')
plt.show()
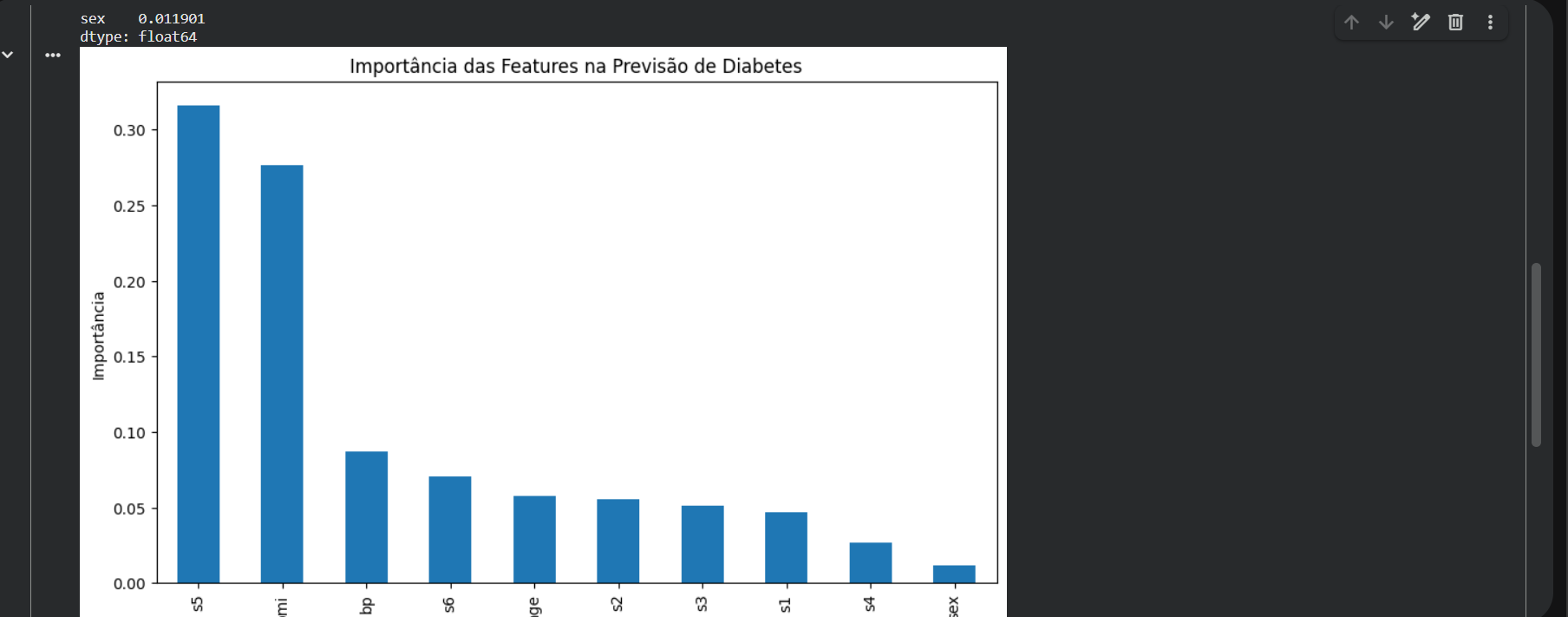
O que foi feito aqui?
Nesta etapa, utilizamos um modelo de Random Forest Regressor para analisar a importância das variáveis no problema de previsão. Isso permite identificar quais características têm maior influência sobre o resultado, ajudando tanto na interpretação quanto na possível simplificação do modelo.
Com essa prática, foi possível perceber que o ajuste de modelos é uma etapa essencial em machine learning. O uso do Grid Search permite encontrar configurações melhores para o algoritmo, aumentando seu desempenho. Já a análise de importância das features ajuda a compreender melhor os dados e identificar quais variáveis realmente influenciam a previsão.
Dessa forma, além de construir modelos preditivos, também conseguimos torná-los mais ajustados, mais eficientes e mais interpretáveis.

