
Pessoal,
Como exercício de aprendizado, comparei o notebook original do curso (com leves ajustes de CPU) com uma versão minha focada em generalização e redução de overfitting. Seguem mudanças e resultados.
Notebooks
Original: https://github.com/carlosvblessa/rn-convolucionais/blob/main/06-TreinoDoZero.ipynb
Minha versão (v2): https://github.com/carlosvblessa/rn-convolucionais/blob/main/06-TreinoDoZero_v2.ipynb
Contexto rápido
- Tarefa: classificação (imagens 32×32).
- Ambiente: CPU, com
num_workers,prefetch, etc., e reprodutibilidade (seeds + determinístico). - Métrica: acurácia de validação (observando gap treino–val).
O que mudei na minha versão (além do original)
Dados / Transforms
- Normalize (por canal, CIFAR-10): aplico ((x-\mu)/\sigma) após
ToTensor()com estatísticas do treino do CIFAR-10, o que estabiliza a otimização e ajuda a convergência. Opacus usaMEAN=(0.4914,0.4822,0.4465)eSTD=(0.2023,0.1994,0.2010). Ref.: https://opacus.ai/tutorials/building_image_classifier - RandomCrop(32, padding=2) e RandomHorizontalFlip: aumentam diversidade e ajudam a conter overfitting.
Perda / Regularização
- CrossEntropyLoss com
label_smoothing=0.05(calibragem/robustez). - Weight Decay no otimizador.
Otimizador e Scheduler
- CosineAnnealingLR (LR decai suave; fim ~3e-5).
- Mantive Adam (com WD).
Disciplina de treino
- Early Stopping e Checkpoint do melhor
val_loss(avaliar sempre o best-val). - EMA (Exponential Moving Average) dos pesos (predições mais estáveis).
Reprodutibilidade e CPU
- Seeds (
random,numpy,torch) +torch.use_deterministic_algorithms(True). - DataLoader com
persistent_workers,prefetch_factor,drop_laste cap de threads nos workers.
Obs.: Arquitetura permaneceu essencialmente a mesma (sem Dropout extra). O ganho veio de pipeline, regularização e política de LR.
Resultados
Original — overfitting evidente: treino ~78% vs validação ~62–65% e val_loss alto (a professora Camila interrompeu o treinamento ao perceber).
Minha versão (v2) — validação estável em ~75.8–76.1%; melhor modelo salvo por val_loss (ex.: epoch 145, val_loss=0.8855, val_acc=76.05%; LR final ~3e-5).
Comparativo resumido
| Aspecto | Original | Minha versão (v2) |
|---|---|---|
| Transforms | Básico (sem normalização) | Normalize + RandomCrop + HorizontalFlip |
| Loss | CrossEntropy | CrossEntropy + Label Smoothing (0.05) |
| Weight Decay | — | Sim |
| Scheduler | — | CosineAnnealingLR |
| Early Stopping / Checkpoint | — | Sim (por val_loss) |
| EMA de pesos | — | Sim |
| Reprodutibilidade | Seeds | Seeds + determinístico |
| Val Acc (faixa) | ~62–65% | ~75.8–76.1% |
| Gap treino–val | ~13 pp | ~1–2 pp (bem controlado) |
| Tempo/época (aprox.) | ~5.8–6.0 s | ~7.2–7.3 s (↑ pelo pipeline) |
Gráficos
Loss por época — Original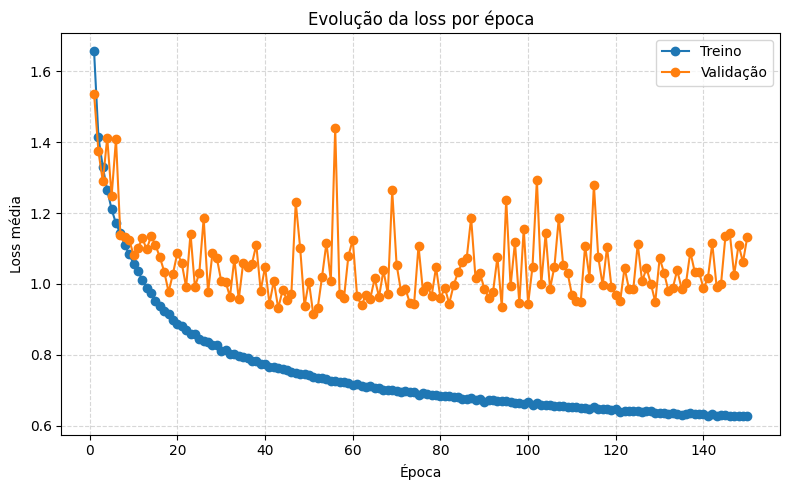
Loss por época — Minha versão (v2)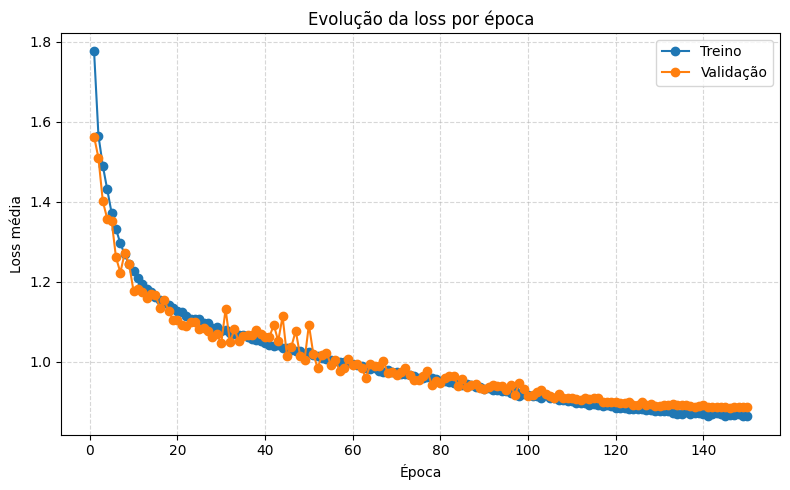
MC - Original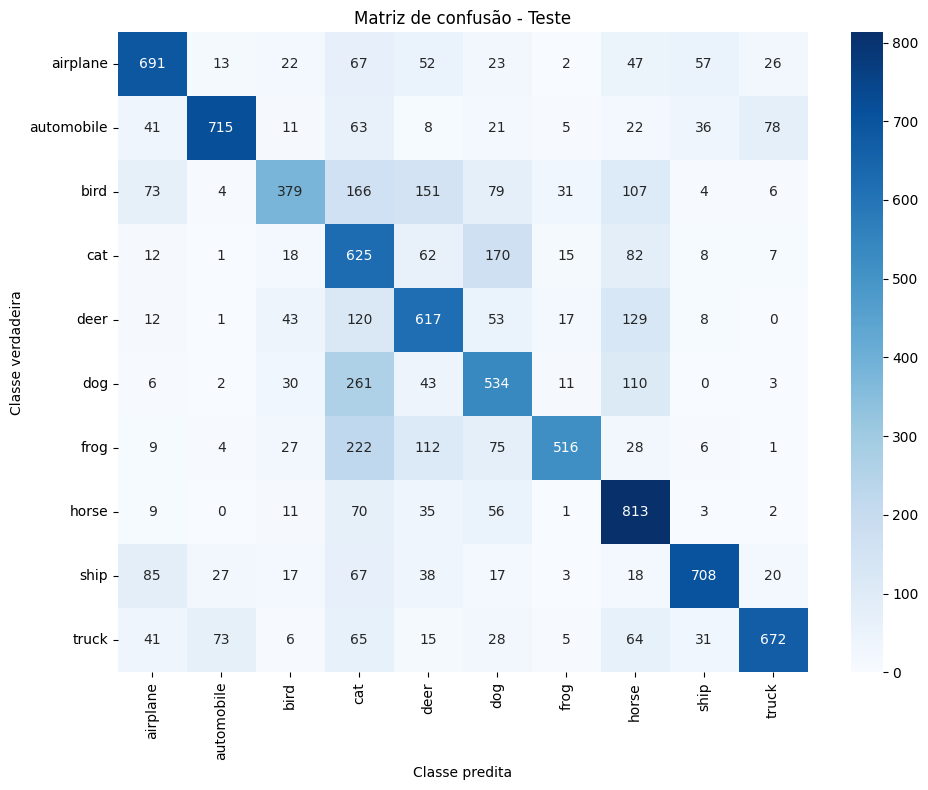
MC - Minha versão (v2)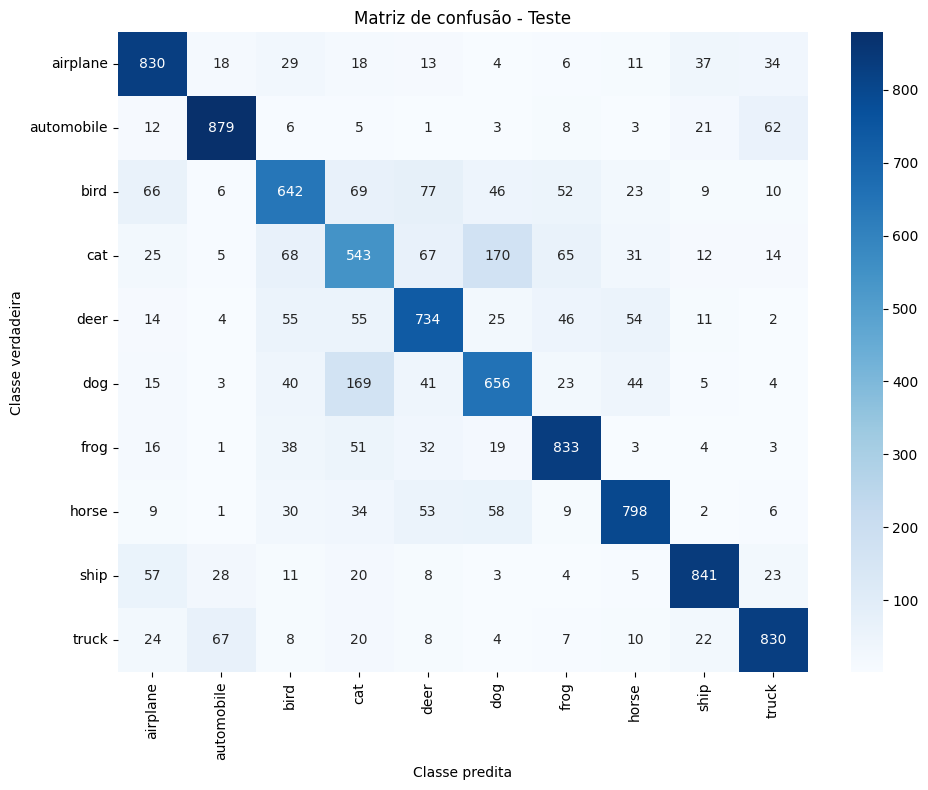
Principais aprendizados
- Augmentação + Normalização mudam o jogo (mais diversidade, sinais mais estáveis).
- Label smoothing (+ WD) melhora generalização sem mudar a rede.
- Cosine LR guia o treino sem “degraus”; fim com LR pequeno ajuda a não superajustar.
- EMA + Early Stopping + Checkpoint garantem uso do melhor ponto de validação.
Estudo pontual: não continuei tunando além disso.
Abraços!

