Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!


Poderiam me ajudar com este erro?

Ei, Guilherme! Tudo bem?
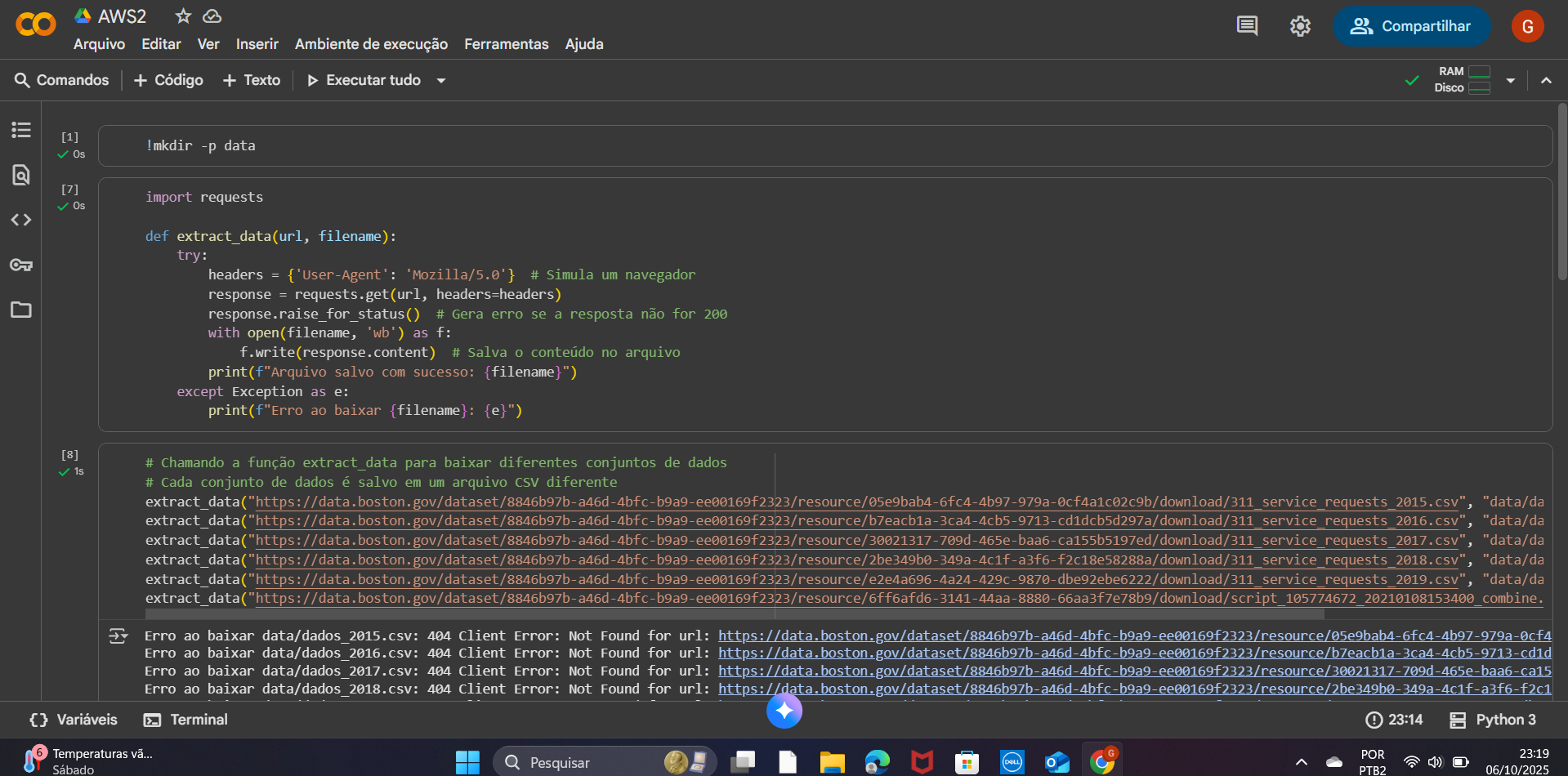
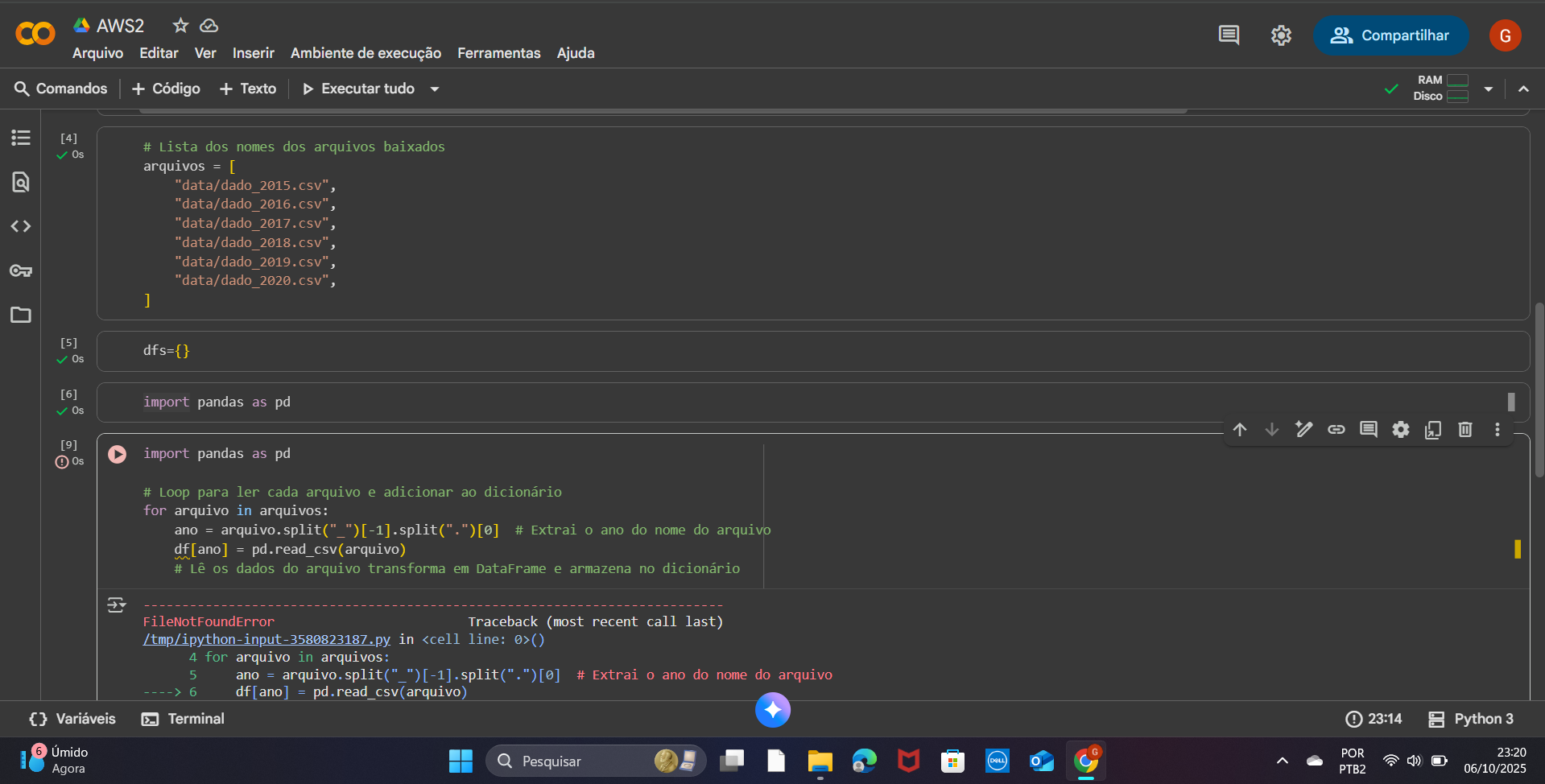
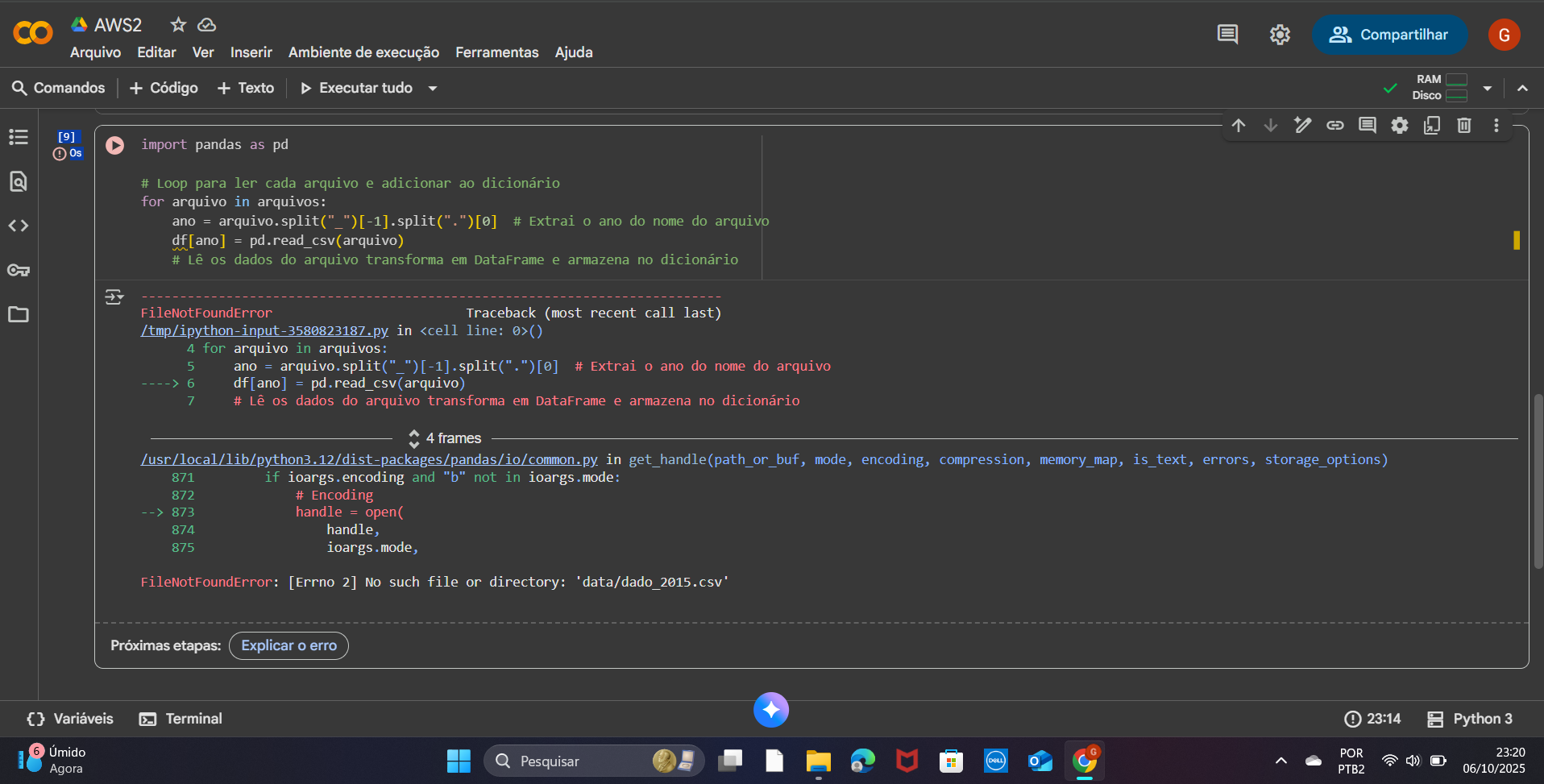
O código não conseguiu baixar o arquivo dados_2015.csv, gerando o erro FileNotFoundError: [Errno 2] No such file or directory: 'data/dados_2015.csv'. Isso aconteceu porque o servidor da Prefeitura de Boston bloqueou a requisição feita pela função urllib.request.urlretrieve().
Servidores muitas vezes rejeitam requisições de scripts que não se identificam como navegadores. A função urlretrieve não envia um cabeçalho "User-Agent", o que faz o servidor detectar a requisição como um bot e bloqueá-la.
Para conseguir baixar os arquivos recomendo que faça o seguinte:
import urllib.request
#Módulo utilizado para fazer o download de dados de uma url
# Função para baixar dados de um URL e salvar em um arquivo
def extract_data(url, filename): #Parâmetros da função que espera 2 argumentos
try:
urllib.request.urlretrieve(url, filename)
# Baixa o arquivo do URL e salva no local especificado
except Exception as e:
print(e) # Imprime qualquer erro que ocorra durante o processo
import requests
def extract_data(url, filename):
try:
headers = {'User-Agent': 'Mozilla/5.0'} # Simula um navegador
response = requests.get(url, headers=headers)
response.raise_for_status() # Gera erro se a resposta não for 200
with open(filename, 'wb') as f:
f.write(response.content) # Salva o conteúdo no arquivo
print(f"Arquivo salvo com sucesso: {filename}")
except Exception as e:
print(f"Erro ao baixar {filename}: {e}")
Sobre o que o código que trocamos faz: A função extract_data recebe uma URL e o nome de um arquivo local. Ela envia uma requisição HTTP à URL usando um cabeçalho User-Agent para simular um navegador. Se a resposta for bem-sucedida (status 200), o conteúdo é salvo no arquivo especificado. Em caso de erros, como URL inválida ou erro 403, uma mensagem de erro é exibida. Assim, a função garante o download correto dos dados, evitando problema de "arquivo não encontrado" ao usar a biblioteca pandas.
Espero ter ajudado e qualquer dúvida, compartilhe no fórum.
Até mais e bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado!