
Ao variar o número de clusters, os resultados não variaram. Também não variaram quando apliquei os valores aleatórios. O que pode estar acontecendo?
Validação dos clusters
def clustering_algorithm (clusters, dataset): kmeans = KMeans(n_clusters = clusters, n_init = 10, max_iter = 300) y_pred = kmeans.fit_predict(dataset) s = metrics.silhouette_score(dataset, labels, metric = 'euclidean') dbs = metrics.davies_bouldin_score(values, labels) calinski = metrics.calinski_harabasz_score(values, labels) return s, dbs, calinski
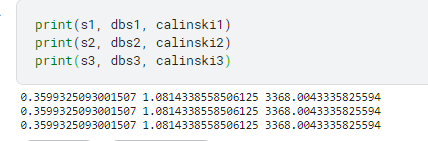
Testando com uma amostra aleatória dos dados
random_data = np.random.rand(8950, 16) s, dbs, calinski = clustering_algorithm(5, random_data) print(s, dbs, calinski) print(s2, dbs2, calinski2)
