Oi Renato! Tudo bem contigo?
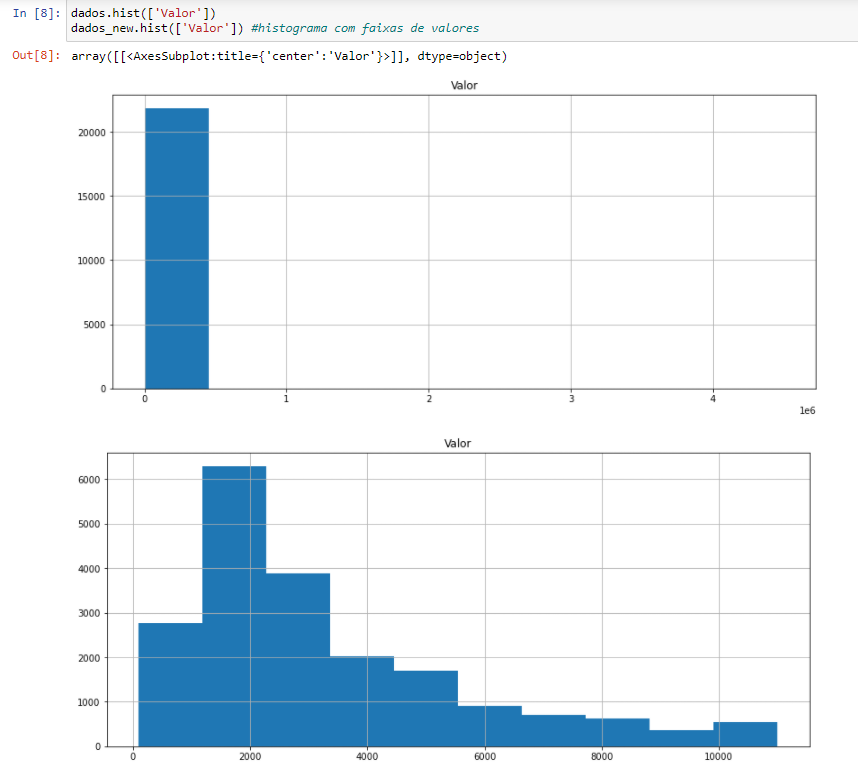
Essa diferença no gráfico se deve pois dados_new representa o dataframe dados sem os outliers.
Observe o eixo x de cada um dos gráficos. Podemos perceber neles que há uma grande diferença quanto a distribuição das escalas. No primeiro gráfico (referente a dados) notamos que os valores variam de 0 a 4, já no segundo gráfico (referente a dados_new) notamos que os valores variam de 0 a 10.00. Há uma distância bem considerável entre essas escalas que dificulta nossa visualização. Mas essa forma de visualização vem muito por conta da existência do outlier que é muito grande e por isso é bem considerável que seja mostrado em um historiograma. No entanto, por ele ter valores bem distantes dos demais dados, o historiograma se resumiu a mostrar apenas esse dado específico.
Além disso, até observando os valores do eixo y, vemos também uma disparidade muito elevada entre os dados mostrados. Mesmo assim, todos os valores da coluna 'Valor' de dados e dados_new foram adquiridos para montar o gráfico, mas como no caso de dados existe um valor bem "absurdo" comparado aos demais, a visualização foi inteiramente focada nele.
Acredito que o objetivo do instrutor nessa análise é perceber o quanto a presença de um Outlier pode nos prejudicar na análise dos dados.
Eu espero ter te ajudado! Se a dúvida persistir, estarei à disposição.
Bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓.Bons Estudos!