!pip install gymnasium matplotlib
import gymnasium as gym
import numpy as np
import random
import matplotlib.pyplot as plt
# Treinamento de agente com Q-Learning:
def train_q_learning(alpha, gamma, epsilon, episodes=2000, test_episodes=100):
env = gym.make("FrozenLake-v1", is_slippery=True)
q_table = np.zeros([env.observation_space.n, env.action_space.n])
rewards_per_episode = []
for episode in range(episodes):
state, _ = env.reset()
done = False
total_reward = 0
while not done:
if random.uniform(0, 1) < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(q_table[state])
next_state, reward, done, truncated, info = env.step(action)
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
new_value = (1 - alpha) * old_value + alpha * (reward + gamma * next_max)
q_table[state, action] = new_value
state = next_state
total_reward += reward
rewards_per_episode.append(total_reward)
# Avaliação sem exploração:
successes = 0
for _ in range(test_episodes):
state, _ = env.reset()
done = False
while not done:
action = np.argmax(q_table[state])
state, reward, done, truncated, info = env.step(action)
if done and reward == 1:
successes += 1
success_rate = successes / test_episodes
return rewards_per_episode, success_rate
# Diferentes combinações de hiperparâmetros:
configs = [
{"alpha":0.8, "gamma":0.95, "epsilon":0.1},
{"alpha":0.5, "gamma":0.99, "epsilon":0.2},
{"alpha":0.9, "gamma":0.9, "epsilon":0.05},
{"alpha":0.7, "gamma":0.8, "epsilon":0.3},
]
results = {}
for i, cfg in enumerate(configs):
rewards, success_rate = train_q_learning(cfg["alpha"], cfg["gamma"], cfg["epsilon"])
results[f"Config {i+1}"] = {
"params": cfg,
"rewards": rewards,
"success_rate": success_rate
}
print(f"Config {i+1} - alpha={cfg['alpha']}, gamma={cfg['gamma']}, epsilon={cfg['epsilon']}")
print(f"Taxa de sucesso: {success_rate*100:.2f}%\n")
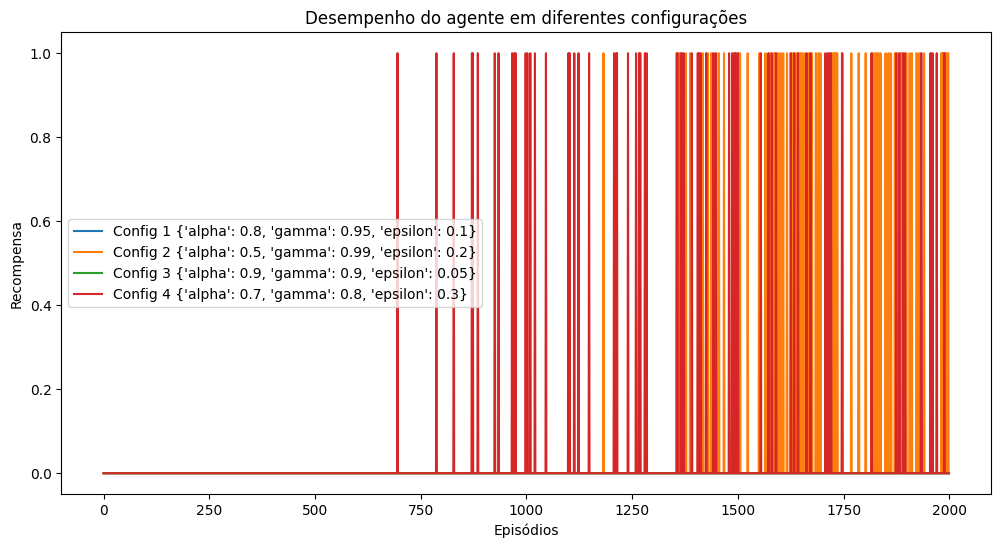
# Plotagem de recompensas por episódio:
plt.figure(figsize=(12,6))
for key, value in results.items():
plt.plot(value["rewards"], label=f"{key} {value['params']}")
plt.xlabel("Episódios")
plt.ylabel("Recompensa")
plt.title("Desempenho do agente em diferentes configurações")
plt.legend()
plt.show()
Requirement already satisfied: gymnasium in /usr/local/lib/python3.12/dist-packages (1.3.0)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.12/dist-packages (3.10.0)
Requirement already satisfied: numpy>=1.21.0 in /usr/local/lib/python3.12/dist-packages (from gymnasium) (2.0.2)
Requirement already satisfied: cloudpickle>=1.2.0 in /usr/local/lib/python3.12/dist-packages (from gymnasium) (3.1.2)
Requirement already satisfied: typing-extensions>=4.3.0 in /usr/local/lib/python3.12/dist-packages (from gymnasium) (4.15.0)
Requirement already satisfied: farama-notifications>=0.0.1 in /usr/local/lib/python3.12/dist-packages (from gymnasium) (0.0.6)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (1.3.3)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (4.63.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (1.5.0)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (26.2)
Requirement already satisfied: pillow>=8 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (11.3.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (3.3.2)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.12/dist-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.12/dist-packages (from python-dateutil>=2.7->matplotlib) (1.17.0)
Config 1 - alpha=0.8, gamma=0.95, epsilon=0.1
Taxa de sucesso: 0.00%
Config 2 - alpha=0.5, gamma=0.99, epsilon=0.2
Taxa de sucesso: 29.00%
Config 3 - alpha=0.9, gamma=0.9, epsilon=0.05
Taxa de sucesso: 0.00%
Config 4 - alpha=0.7, gamma=0.8, epsilon=0.3
Taxa de sucesso: 4.00%