
Calcule o desvio padrão amostral das avaliações.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
# Conjunto de dados TechTaste
df_techtaste = pd.DataFrame({'avaliacoes': [38, 44, 33, 42, 47, 33, 36, 39, 42, 36, 39, 34, 42, 42, 36, 43, 31, 35, 36, 41, 42, 30, 25, 38, 47, 36, 32, 45, 44, 45, 37, 48, 37, 36, 44, 49, 31, 45, 45, 40, 36, 5
dp = df_techtaste['avaliacoes'].std()
print(f'Desvio padrão: {dp:.2f}')
Calcule o erro padrão amostral da média para as avaliações dos clientes.
tamanho_amostra = len(df_techtaste)
er = dp/np.sqrt(tamanho_amostra)
print(f'Erro padrão: {er:.2f}')
Utilizando um gráfico de histograma, analise visualmente a distribuição das avaliações dos clientes.
plt.hist(df_techtaste['avaliacoes'], bins = 20, alpha = 0.7, color = 'green' )
plt.title('Frequência das avaliações dos clientes')
plt.xlabel('Notas')
plt.ylabel('frequência')
plt.show()
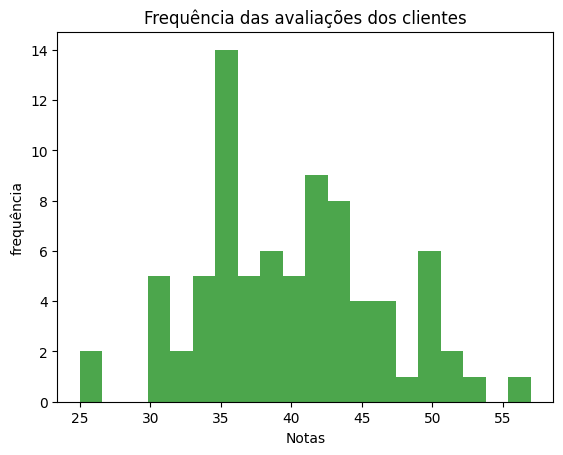
Observe o formato da distribuição gerado no histograma. Ele se assemelha a uma distribuição normal?
sns.kdeplot(df_techtaste['avaliacoes'], fill = True)
plt.title('Distribuição das avaliações dos clientes')
plt.xlabel('Notas')
plt.ylabel('Distribuição')
plt.show()
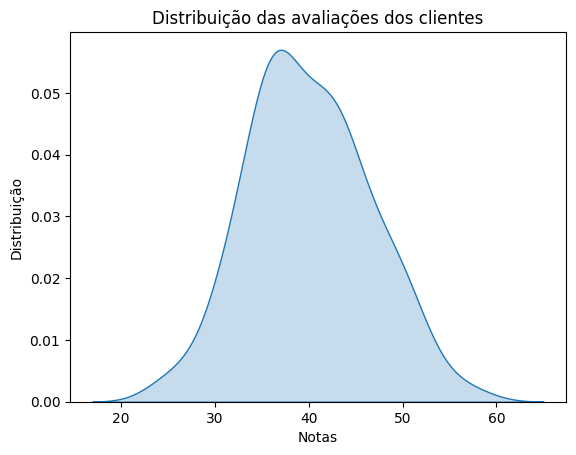
Com um nível de confiança de 90%, calcule o intervalo de confiança para a média das avaliações.
confianca = 0.9
media = df_techtaste['avaliacoes'].mean()
intervalo_confianca = stats.norm.interval(confianca,
loc = media ,
scale = er)
print(f'Intervalo de Confiança ({confianca*100}%): {intervalo_confianca}')
A largura do intervalo de confiança seria afetada se o nível de confiança fosse aumentado para 95%?
confianca = 0.95
media = df_techtaste['avaliacoes'].mean()
intervalo_confianca = stats.norm.interval(confianca,
loc = media ,
scale = er)
print(f'Intervalo de Confiança ({confianca*100}%): {intervalo_confianca}')

