import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
import numpy as np
# Conjunto de dados TechTaste
df_techtaste = pd.DataFrame({'avaliacoes': [38, 44, 33, 42, 47, 33, 36, 39, 42, 36, 39, 34, 42, 42, 36, 43, 31,
35, 36, 41, 42, 30, 25, 38, 47, 36, 32, 45, 44, 45, 37, 48, 37, 36,
44, 49, 31, 45, 45, 40, 36, 50, 38, 34, 36, 42, 46, 49, 36, 34, 38,
31, 53, 40, 57, 40, 36, 42, 26, 50, 32, 43, 35, 37, 42, 30, 36, 43,
40, 43, 44, 52, 37, 51, 35, 47, 40, 50, 37, 49]})
#Checando quantidade de avaliações
df_techtaste['avaliacoes'].value_counts()
#Calcule o desvio padrão amostral das avaliações.
print(f'O desvio padrão é: {df_techtaste['avaliacoes'].std()}')
#O desvio padrão é: 6.421827887581659
#Calcule o erro padrão amostral da média para as avaliações dos clientes.
print(f'O erro padrão é: {stats.sem(df_techtaste['avaliacoes'])}')
#O erro padrão é: 0.7179821848218233
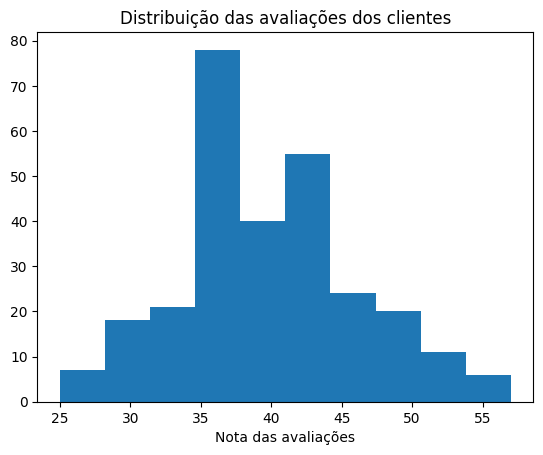
#Utilizando um gráfico de histograma, analise visualmente a distribuição das avaliações dos clientes.
plt.hist(df_techtaste['avaliacoes'])
plt.title('Distribuição das avaliações dos clientes')
plt.xlabel('Nota das avaliações')
plt.show()
Observe o formato da distribuição gerado no histograma. Ele se assemelha a uma distribuição normal?
Sim, assemelha-se a uma distribuição normal, apesar da irregularidade no meio do gráfico. Observa-se que as pontas direita e esquerda vão aumentando gradativamente ao centro com pico próximo de 35 e 45. Levemente lembra o formato de um sino.
#Com um nível de confiança de 90%, calcule o intervalo de confiança para a média das avaliações.
confianca = 0.90
media = df_techtaste['avaliacoes'].mean()
desvio_padrao_amostra = df_techtaste['avaliacoes'].std()
tamanho_amostra = len(df_techtaste)
intervalo_confianca = stats.norm.interval(
confianca, #nível de confiança
loc = media, #onde será adicionada margem de erro (localização)
scale = desvio_padrao_amostra / np.sqrt(tamanho_amostra) #variabilidade do intervalo - cálculo do erro padrão
)
print('Intervalo de confiança (90%): ', intervalo_confianca)
#Intervalo de confiança (90%): (np.float64(38.84402439920928), np.float64(41.205975600790715))
#A largura do intervalo de confiança seria afetada se o nível de confiança fosse aumentado para 95%?
confianca = 0.95
intervalo_confianca = stats.norm.interval(
confianca, #nível de confiança
loc = media, #onde será adicionada margem de erro (localização)
scale = desvio_padrao_amostra / np.sqrt(tamanho_amostra) #variabilidade do intervalo - cálculo do erro padrão
)
print('Intervalo de confiança (95%): ', intervalo_confianca)
#A largura é afetada levemente, diminuindo casas decimais no mínimo e aumentando casas decimais no máximo
#Intervalo de confiança (95%): (np.float64(38.617780776207844), np.float64(41.43221922379215))