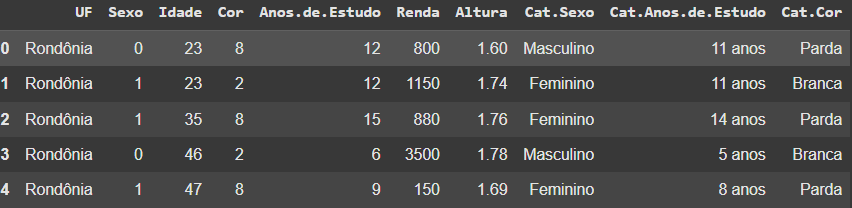
sexo = {0: 'Masculino', 1: 'Feminino'}
cor = {0:'Indígena', 2:'Branca', 4:'Preta', 6:'Amarela', 8:'Parda'}
anos_de_estudo = {1:'Sem instrução e menos de 1 ano', 2:'1 ano', 3:'2 anos', 4:'3 anos', 5:'4 anos', 6:'5 anos',
7:'6 anos', 8:'7 anos', 9:'8 anos', 10:'9 anos', 11:'10 anos', 12:'11 anos', 13:'12 anos',14:'13 anos',
15:'14 anos', 16:'15 anos ou mais', 17:'Não determinados'
}
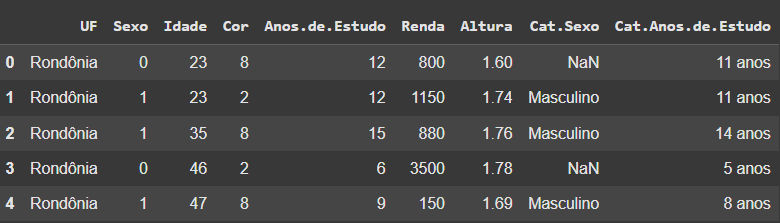
dados['Cat.Sexo'] = pd.Categorical(
dados['Sexo'],
categories=[0,1],
ordered=True
)
dados['Cat.Sexo'] = dados['Cat.Sexo'].map(sexo)
dados.head()
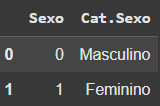
dados_distintos = dados[['Sexo', 'Cat.Sexo']].drop_duplicates()
dados_distintos
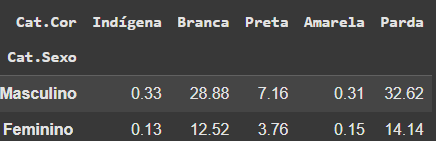
freq_relativa = round(pd.crosstab(dados['Cat.Sexo'], dados['Cat.Cor'], normalize = 'all') * 100,2)
freq_relativa
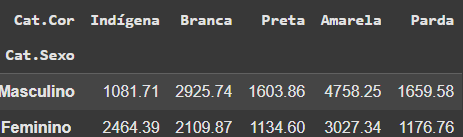
ticket_medio = round(pd.crosstab(dados['Cat.Sexo'], dados['Cat.Cor'], values=dados['Renda'], aggfunc='mean'), 2)
ticket_medio
dados['Cat.Sexo'] = pd.Categorical(dados['Sexo'], categories=[0, 1], ordered=True)
dados['Cat.Cor'] = pd.Categorical(dados['Cor'], categories=[0, 2, 4, 6, 8], ordered=True)
dados['Cat.Sexo'] = dados['Cat.Sexo'].map(sexo)
dados['Cat.Cor'] = dados['Cat.Cor'].map(cor)
tabela_cruzada = pd.pivot_table(dados, values='Renda', index='Cat.Sexo', columns='Cat.Cor', aggfunc='mean')
# Exibindo a tabela cruzada
dados.head()