
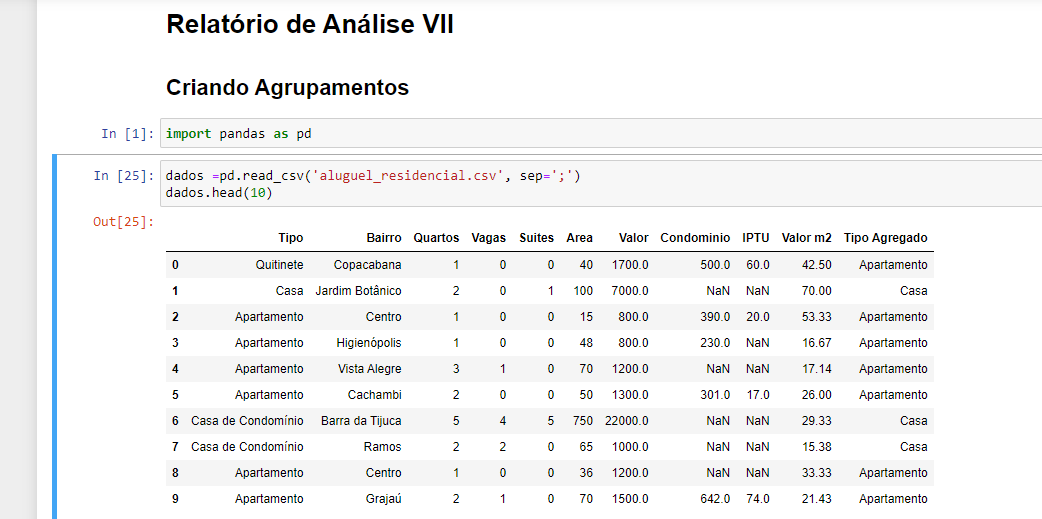
Boa tarde! Estou realizando os exercícios juntamente da aula, e identifiquei duas coisas:
1) A index do meu dataframe não está correta; como eu posso corrigir ela?
(Ela está começando em 0 ao invés de começar em 1 )
2) O resultado final do meu exercício não está numericamente igual ao do professor:
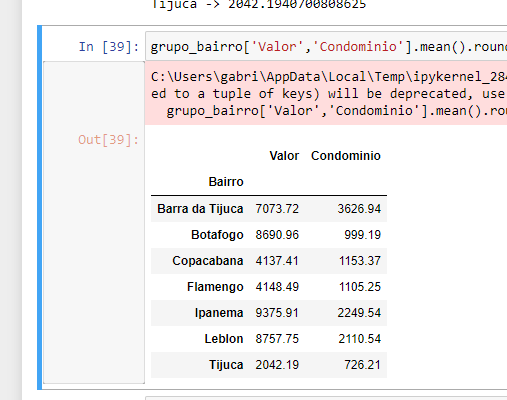
(Esse é o meu resultado)
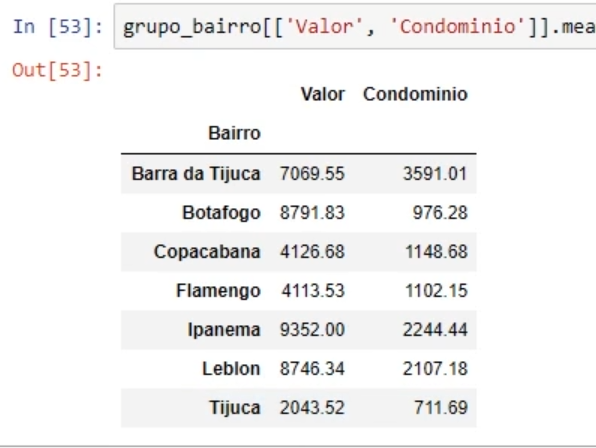
(Esse é o resultado da aula do professor - note a diferença dos valores numéricos entre as duas imagens). Desconfio que o problema (2) está relacionado ao problema (1). Segue em anexo um print do meu código.
import pandas as pd
dados =pd.read_csv('aluguel_residencial.csv', sep=';')
dados.head(10)bairros = ['Barra da Tijuca', 'Copacabana', 'Ipanema', 'Leblon', 'Botafogo', 'Flamengo', 'Tijuca']
selecao = dados ['Bairro'].isin(bairros)
dados = dados[selecao]dados['Bairro'].drop_duplicates()grupo_bairro = dados.groupby('Bairro')type(grupo_bairro)grupo_bairro.groupsfor bairro, dados in grupo_bairro:
print ('{} -> {}'.format(bairro, dados['Valor'].mean()))grupo_bairro['Valor','Condominio'].mean().round(2)
