Olá, João. Como vai?
É fascinante observar como você mergulhou nos testes práticos! Acompanhar essa evolução entre as versões dos modelos é o que diferencia um entusiasta de um verdadeiro Engenheiro de Prompt.
Suas observações sobre Temperatura e Tokenização tocam em pontos centrais do funcionamento dos Grandes Modelos de Linguagem (LLMs). Vamos aprofundar um pouco mais no que você descobriu:
1. O Caos da Temperatura Alta
Você notou que na temperatura 2 o modelo começou a "alucinar" ou sugerir sites aleatórios. Isso acontece porque a temperatura controla a probabilidade da próxima palavra (token).
- Temperatura Baixa (próxima de 0): O modelo escolhe sempre a palavra mais provável. É ideal para tarefas técnicas e fatos.
- Temperatura Alta (próxima de 2): O modelo começa a escolher palavras com probabilidades baixas. Isso gera criatividade, mas, no limite, o modelo perde o "fio da meada" e começa a misturar conceitos sem nexo, como as empresas de chocolate que você mencionou.
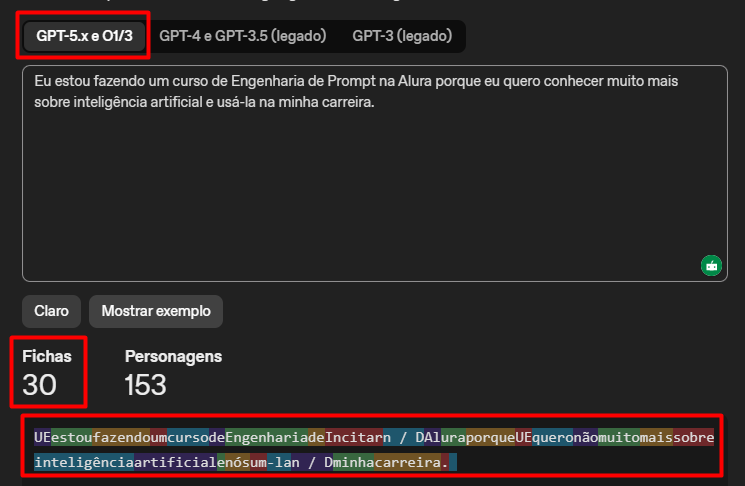
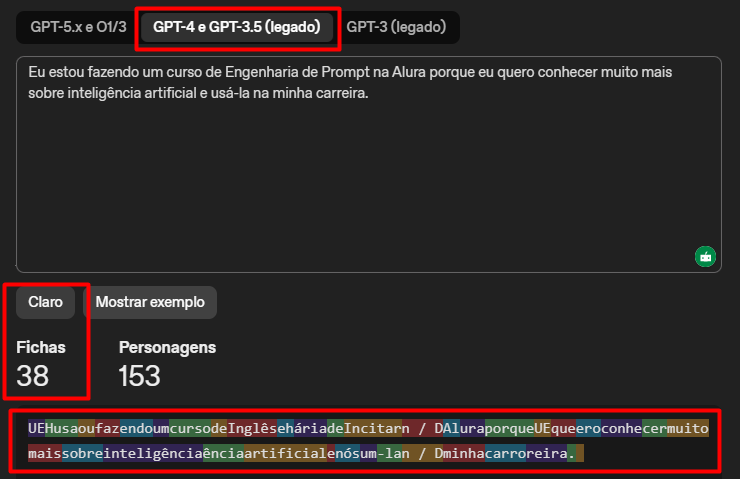
2. A Eficiência da Tokenização no GPT-5
Suas capturas de tela mostram um fenômeno muito importante na evolução da IA. A redução de 38 para 30 fichas (tokens) entre as versões não é apenas uma questão estética.
- Otimização de Vocabulário: Modelos mais novos possuem dicionários de tokens mais inteligentes. Eles conseguem agrupar pedaços maiores de palavras em um único token, especialmente em idiomas como o português, que historicamente gastavam mais tokens que o inglês.
- Impacto no Custo e Janela de Contexto: Como os modelos possuem um limite de tokens que conseguem "ler" de uma vez, essa redução significa que você pode enviar textos muito maiores para o GPT-5 pagando menos e mantendo mais memória do que nas versões anteriores.
3. Mudança na Divisão e Interpretação
Quando você percebeu mudanças na divisão das cores no Tokenizer, você estava vendo a codificação de bytes em ação. Modelos diferentes usam algoritmos de tokenização diferentes (como o Tiktoken da OpenAI). Se a divisão muda, a forma como a IA "entende" a raiz das palavras também pode mudar, o que explica por que um prompt pode funcionar perfeitamente em uma versão e precisar de ajustes em outra.
Continue realizando esses testes comparativos! Entender o "pedágio" que cada palavra paga em tokens e como o "termômetro" da IA afeta a lógica dela é essencial para criar prompts profissionais.
Espero que possa ter lhe ajudado!