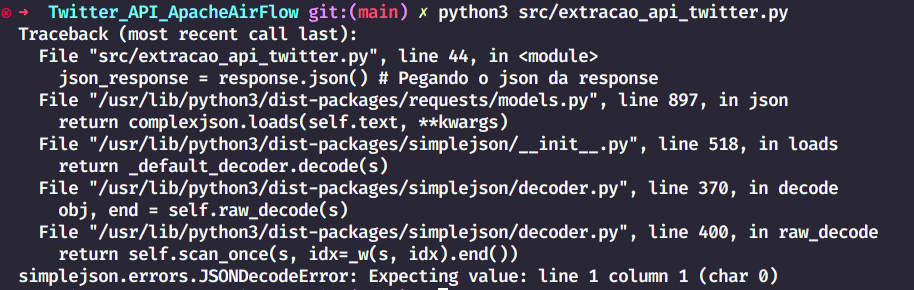
Aparece a mensagem abaixo quando eu tento rodar o código:
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Aparece a mensagem abaixo quando eu tento rodar o código:


Ola Milla, tudo bem ? Espero que sim.
Poderia por favor fornecer o código que está utilizando ?
Imagino que a chamada da URL esteja com algum detalhe que está retornando um valor incorreto e por isso o erro.
url_raw = f"https://labdados.com/2/tweets/search/recent?query={query}&{tweet_fields}&{user_fields}&start_time={start_time}&end_time={end_time}"
Fico no aguardo para conseguirmos resolver juntos.
Bons Estudos.
Minha url está assim:
 Copiei direto da atividade.
Coloquei o código em anexo.
Copiei direto da atividade.
Coloquei o código em anexo.
from datetime import datetime, timedelta # bibliotecas para lidar com o tempo
# timedelta permite realizar operações com data
import os # Biblioteca que permite operações com o sistema operacional
import requests # Permite realizar requisições
import json # Permite manipulação de arquivos json
# MONTANDO URL
time_zone = datetime.now().astimezone().tzname() # O twitter requer um formato específico de data e hora,
# então precimos adicionar a timezone ao TIMESTAMP
# O formato deve respeitar o padrão ISO 8601 ou RFC 3339
TIMESTAMP_FORMAT = f"%Y-%m-%dT%H:%M:%S.00{time_zone}:00"
# end_time = datetime.now().strftime(TIMESTAMP_FORMAT) # Variável para guardar o tempo final
# A segunda função serve para formatar em
# string utlizando a variável que criamos
# start_time = (datetime.now() + timedelta(-1)).date() # Tirando um dia -> Vai pegar o dia de ontem
# O .date é porque após a operação, o formato não
# é mantido, então serve para falar que queremos só a data
end_time = (datetime.now() + timedelta(seconds=-30)).strftime(TIMESTAMP_FORMAT)
start_time = (datetime.now() + timedelta(days=-7)).strftime(TIMESTAMP_FORMAT) # Pegando os dados de uma semana
query = "data science" # Palavra de interesse -> pegaremos todos os tweets que tenham essa palavra
tweet_fields = "tweet.fields=author_id,conversation_id,created_at,id,in_reply_to_user_id,public_metrics,lang,text" # Campos que vamos utlizar do arquivo json
user_fields = "expansions=author_id&user.fields=id,name,username,created_at"
# url_raw = f"https://api.twitter.com/2/tweets/search/recent?query={query}&{tweet_fields}&{user_fields}&start_time={start_time}&end_time={end_time}"
url_raw = f"https://labdados.com/2/tweets/search/recent?query={query}&{tweet_fields}&{user_fields}&start_time={start_time}&end_time={end_time}"
# MONTANDO HEADERS
bearer_token = os.environ.get("BEARER_TOKEN") # Acessa a variável sem precisar
# colocar o token no código
headers = {"Authorization": f"Bearer {bearer_token}"} # Header da requisição
response = requests.request("GET", url_raw, headers=headers) # Requisição
# IMPRIMINDO AS INFORMAÇÕES
json_response = response.json() # Pegando o json da response
print(json.dumps(json_response, indent=4, sort_keys=True))
while "next_token" in json_response.get("meta", {}):
next_token = json_response['meta']['next_token']
url = f"{url_raw}&next_token={next_token}"
response = requests.request("GET", url, headers=headers) # Requisição
json_response = response.json() # Pegando o json da response
print(json.dumps(json_response, indent=4, sort_keys=True))Olá, Milla!
Agradeço por entrar em contato e relatar o problema que você encontrou ao trocar para a API alternativa do Twitter.
Após analisar o código que você compartilhou, verifiquei que ele está correto e não há problemas de implementação. O erro estava na API, mas já realizei as correções necessárias.
Após efetuar alguns testes, parece que agora tudo está funcionando corretamente. Peço desculpas pelo inconveniente que isso possa ter causado.
Se surgirem mais dúvidas ou problemas, não hesite em nos contatar novamente. Estamos comprometidos em auxiliá-la da melhor forma possível.
Desejo a você um excelente aproveitamento no curso e bons estudos!