Bom dia!
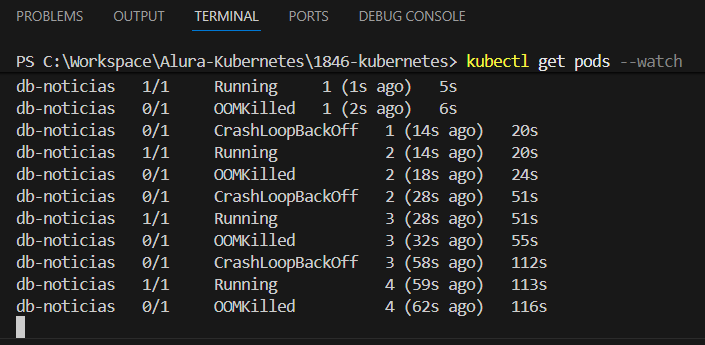
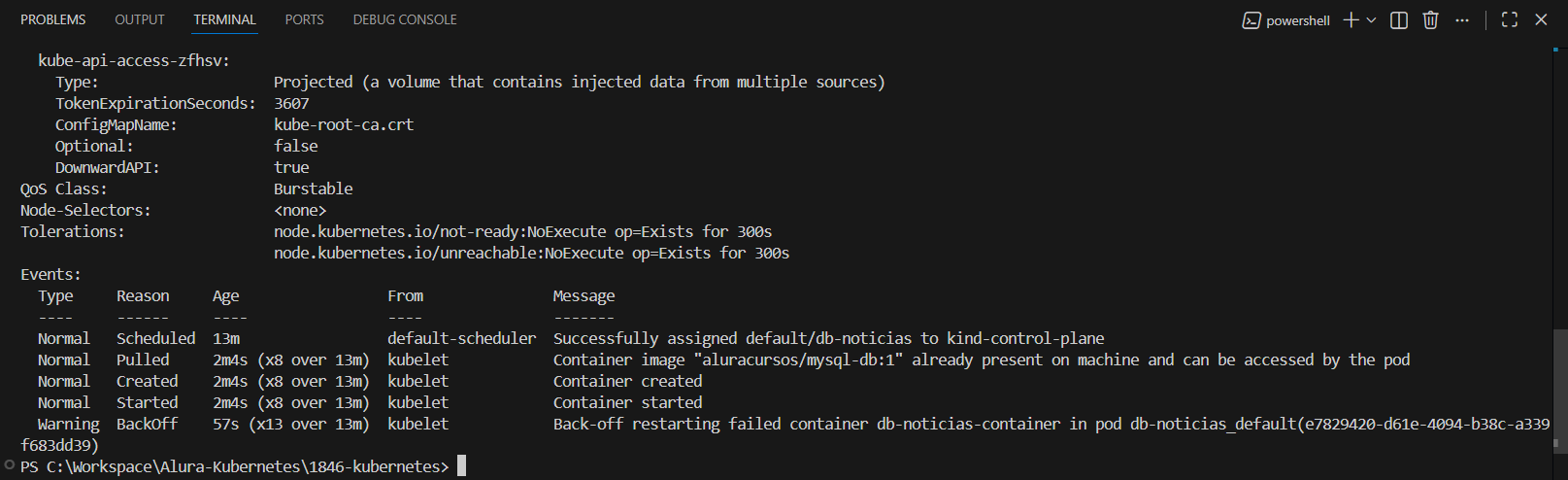
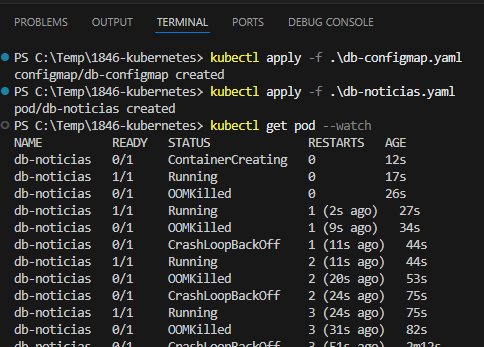
Esse comportamento está bem claro nos prints: o container do MySQL está sendo morto por OOMKilled, entra em CrashLoopBackOff, sobe de novo, estoura memória, morre… e o ciclo se repete.
O ponto-chave aqui é que o problema não está no YAML do Pod, nem no ConfigMap, nem no Service. O problema é o ambiente (Podman + WSL + kind).
O MySQL 5.6 (essa imagem aluracursos/mysql-db:1) consome bem mais memória na inicialização do que parece, principalmente quando roda dentro de um cluster kind que já está dentro de um container Podman, que por sua vez roda dentro do WSL. Na prática, você tem três camadas de limitação de memória.
Mesmo você declarando limits.memory: 2Gi, isso não garante que essa memória esteja realmente disponível. O OOMKilled vem do kernel do container host (Podman/WSL), não do Kubernetes em si.
Isso explica dois sintomas importantes:
- O log do MySQL não mostra erro (ele morre abruptamente).
- O pod chega a ficar
Running por alguns segundos antes de cair.
Em ambiente com Docker Desktop, isso normalmente não acontece. Com Podman + WSL, é comum.
O que resolve de verdade:
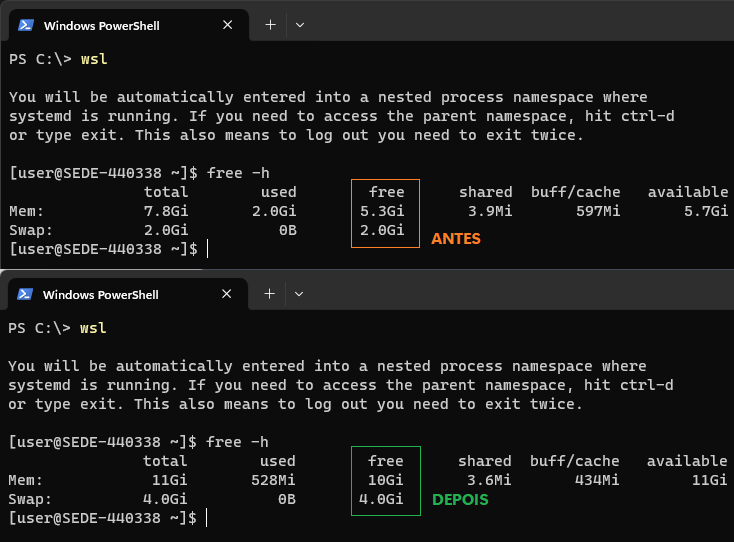
- Aumentar a memória disponível para o WSL
Se o WSL estiver limitado (ex: 2GB ou 4GB), o MySQL simplesmente não sobrevive.
Crie ou ajuste o arquivo ~/.wslconfig no Windows:
[wsl2]
memory=6GB
processors=4
Depois disso, reinicie o WSL:
wsl --shutdown
Recriar o cluster kind depois disso
O kind só “vê” os recursos no momento da criação do cluster. Não adianta só reiniciar o pod.
Se ainda quiser testar rápido, reduzir o consumo do MySQL
Como workaround (não ideal para o curso), você pode:
- Remover
limits de memória temporariamente, ou - Usar uma imagem de MySQL mais leve (ex: 5.7 ou MariaDB)
Mas, para seguir o curso como foi pensado, o caminho correto é dar mais memória ao WSL.
Então:
O pod não para em pé porque não existe memória real suficiente no host, apesar do Kubernetes “achar” que existe. Não é erro seu nem do repositório é limitação clássica de Podman + WSL rodando MySQL.