O que pode ter dado errado aqui?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

O que pode ter dado errado aqui?


Olá, Gabriel. Como vai?
Esse é um erro clássico, mas muito importante quando estamos trabalhando com Machine Learning e a biblioteca scikit-learn (sklearn). Vamos direto ao ponto para entender o que o Python está tentando te dizer.
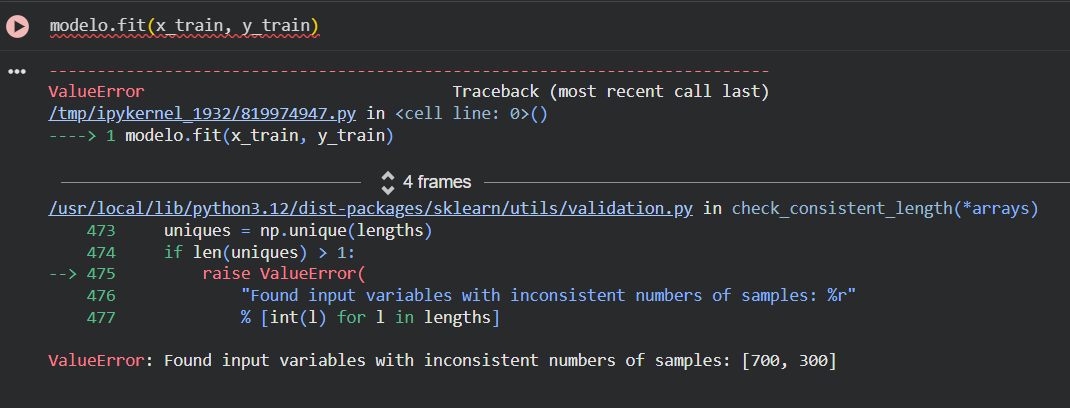
O cerne do problema está na última linha do seu Traceback:ValueError: Found input variables with inconsistent numbers of samples: [700, 300]
Para que qualquer modelo de Machine Learning consiga treinar através do método .fit(X, y), ele exige uma regra matemática básica: o número de linhas (amostras) de $X$ (seus dados de treino) precisa ser exatamente igual ao número de linhas de $y$ (suas respostas/gabarito).
O erro indica que o seu x_train possui 700 linhas, enquanto o seu y_train possui apenas 300 linhas. Como o modelo tenta cruzar os dados linha por linha para aprender a relação de regressão entre eles, ao chegar na linha 301 ele fica sem correspondência e interrompe a execução.
Na maior parte das vezes, isso acontece por uma pequena distração na etapa anterior, durante a divisão dos dados entre treino e teste com a função train_test_split.
O mapeamento padrão correto da função deve seguir rigorosamente a ordem: X_train, X_test, y_train, y_test. Se invertermos a ordem das variáveis receptoras ou errarmos a proporção, o Python gera esse conflito.
Por exemplo, se o seu dataset total possui 1000 linhas e você definiu um test_size=0.3 (30% para teste e 70% para treino), o comportamento esperado é:
x_train e y_train devem ter 700 amostras.x_test e y_test devem ter 300 amostras.O seu y_train acabou recebendo, por engano, a fatia que deveria ir para o teste (y_test).
Volte até a célula do seu código onde você realizou a separação dos dados e verifique se a linha do train_test_split está escrita exatamente assim:
from sklearn.model_selection import train_test_split
# Certifique-se de que a ordem das 4 variáveis à esquerda seja exatamente esta:
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Dica de ouro para checagem: Antes de rodar a célula do modelo.fit(), crie uma célula temporária e verifique o tamanho dos seus conjuntos usando o atributo .shape ou a função len(). Rode o seguinte comando:
print(f"Formato de x_train: {x_train.shape}")
print(f"Formato de y_train: {y_train.shape}")
Se a primeira dimensão (o número de linhas) de ambos não for idêntica, o erro persistirá.
Ajuste a ordem das variáveis no seu train_test_split, execute novamente as células de divisão e o seu modelo.fit(x_train, y_train) passará sem nenhum problema!
Espero que possa ter lhe ajudado!