Olá Luana! Tudo certo? Espero que sim! 🙂
O motivo do professor utilizar o dataframe original novamente é que uma análise conjunta de todos as categorias do campo "Tipo" é diferente de uma análise com as categorais separadas.
Antes de mais nada, vamos dar uma olhada em certos pontos...
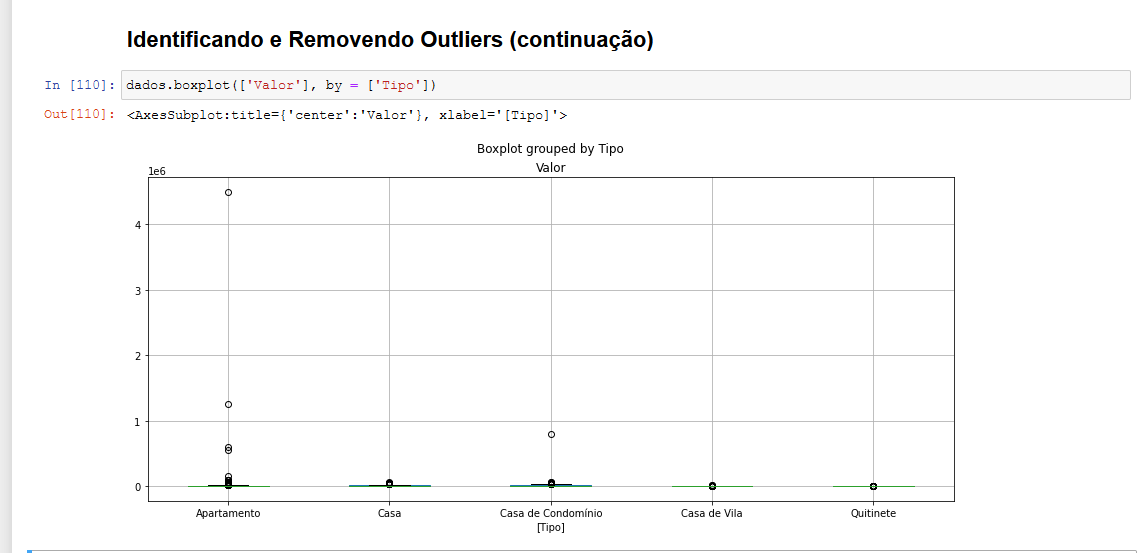
Repare no box-plot feito a partir das das categorias do campo "Tipo" separadas:
Cada categoria apresenta uma dispersão de valores respectivos diferentes. (Faz sentido, uma vez que quitinetes tendem a ser mais baratas que casas).
Note que a maioria dos valores da categoria Casa de Condomínio se encontra acima da marca de 5000.
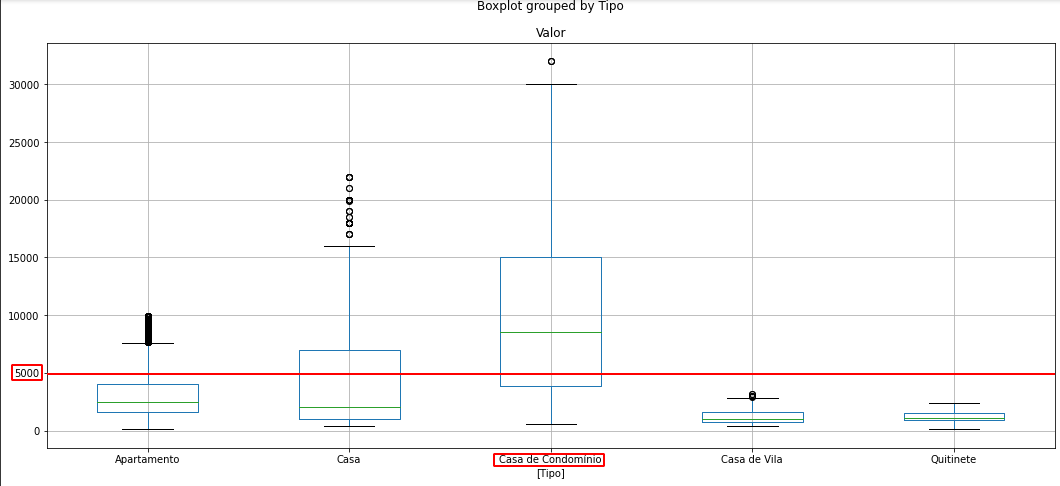
Agora veja a analise em que não é considerado o campo "Tipo":
Todos os valores do dataframe são colocados sob um único "imóvel" incógnita qualquer.
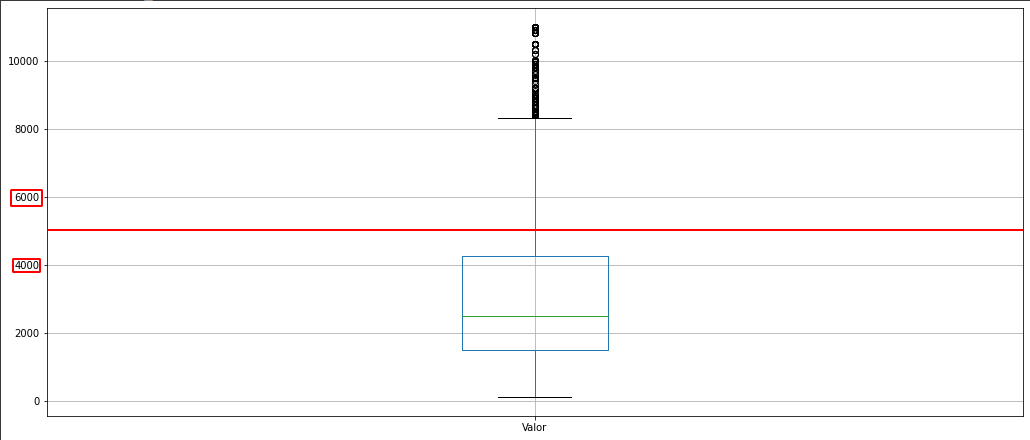
Veja como a maioria dos valores se encontram abaixo da marca de 5000. Isso ocorre devido ao fato da maioria dos valores das categorias de "Tipos" estarem abaixo de 5000, em detrimento de alguns poucos de Casa de Condomínio, que estão acima de 5000. Dessa forma, o diagrama de caixa de acaba sendo "puxado" para baixo e os valores acima da marca de 5000 acabam por ser poucos ou outliers.
Para mais informações sobre os conceitos do Diagrama de Caixa (Box-plot) você pode acessar essas páginas:
Ufa! 😅
Pronto! Agora, voltando à sua questão...
O professor teve que realizar uma nova análise com o dataframe original, pois, justamente, se usasse o antigo e o separasse em categorias de "Tipo", este iria gerar um box-plot com categorias que tiveram seus valores respectivos inteferindo uns com os outros.
Espero ter ajudado! Qualquer dúvida é só falar! 😉
Bons Estudos!