Oii Gabriel!
Claro que posso tentar explicar melhor!
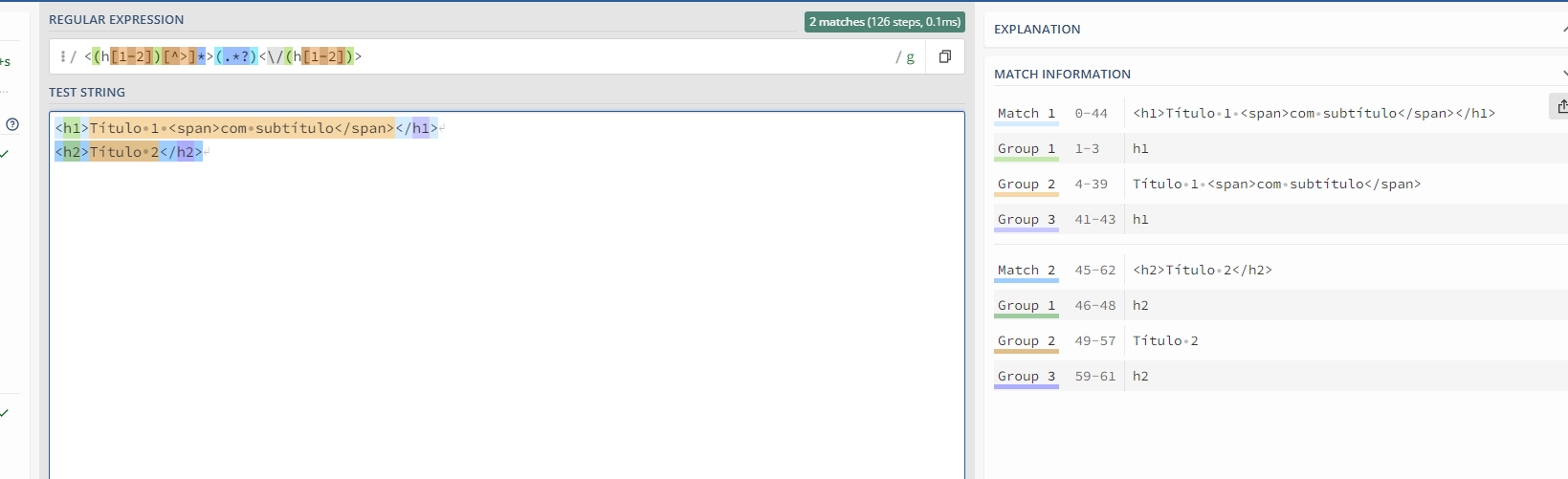
Quanto à quebra de linhas no Colab, a utilização do ponto de interrogação pode afetar como as correspondências são feitas, e isso pode influenciar na quebra de linhas no resultado final. Sem o ponto de interrogação, a expressão pode tentar incluir quebras de linha na correspondência, resultando em uma única linha contendo várias quebras de linha. Com o ponto de interrogação, a correspondência é mais restrita, evitando quebras de linha.
Então, o ponto de interrogação ajuda a controlar o comportamento "ganancioso" ou "não ganancioso" da expressão regular, influenciando como ela lida com caracteres, incluindo quebras de linha, ao fazer correspondências entre tags.
Agora vamos falar sobre a diferença entre "greedy" (ganancioso) e "lazy" (não ganancioso) nas expressões regulares.
"Greedy" (Ganancioso):
Quando você usa uma expressão regular sem o ponto de interrogação, ela se comporta de maneira "gananciosa". Isso significa que ela tenta fazer a correspondência com o maior número possível de caracteres. Veja esse exemplo::
<h1>.*</h1>
Essa expressão tentará corresponder ao texto entre <h1> e </h1>, incluindo o máximo possível de caracteres no meio, até encontrar a última ocorrência de </h1>.
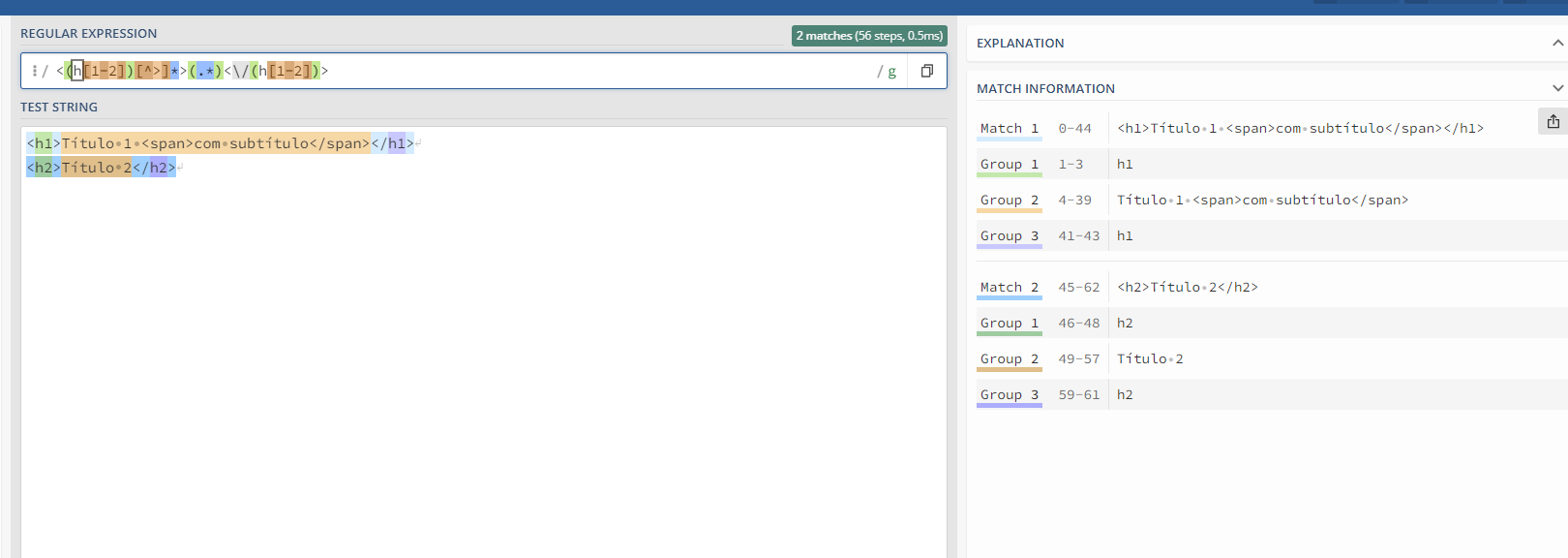
"Lazy" (Não Ganancioso):
Ao adicionar o ponto de interrogação após um quantificador (como *, +, ?), você torna a expressão regular "lazy". Isso significa que ela tentará corresponder com o menor número possível de caracteres.
<h1>.*?</h1>
Neste caso, a expressão tentará corresponder ao texto entre <h1> e </h1>, mas de uma forma mais restrita, pegando o menor número possível de caracteres até encontrar a primeira ocorrência de </h1>. Isso evita que a correspondência "ultrapasse" múltiplas tags de fechamento.
Sobre a aula ter sido vaga, peço que você ao final do curso você deixe um depoimento contando sobre como foi a sua experiência com o curso, pois as pessoas responsáveis estão sempre de olho nos comentários para sempre melhorarmos os conteúdos da plataforma.
Espero que tenha te ajudado.
Um abraço e bons estudos.