Olá, Jean! Tudo certo?
Muito bom ver que você está atento ao trade-off entre recall e precisão!
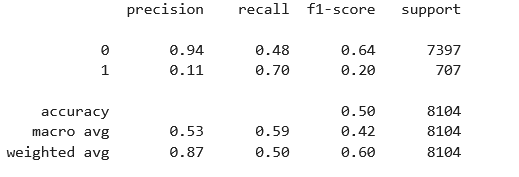
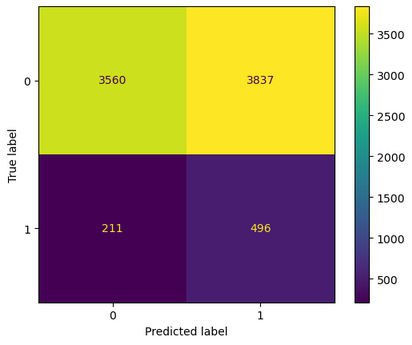
Você observou corretamente: o modelo apresenta um recall de 70% para inadimplentes (classe 1), o que significa que ele está identificando bem quem pode não pagar. Mas, a precisão é de apenas 11%, ou seja, a maioria dos clientes classificados como inadimplentes na verdade não são.
E aí vem a pergunta: o modelo está bom ou não? Depende do contexto do negócio. Vamos pensar nos dois tipos de erro:
Falso positivo (classificar um bom pagador como inadimplente):
Pode significar perda de um cliente confiável, impacto na receita ou até danos à imagem da empresa.
Falso negativo (deixar passar um inadimplente):
Representa um risco financeiro direto, com impacto na taxa de perdas.
Com isso, a decisão depende de qual tipo de erro sua empresa tolera mais.
O que pode ser feito a partir daqui?
Ajustar o limiar de decisão:
O modelo provavelmente está usando o limiar padrão de 0.5. Ajustar esse valor pode ajudar a encontrar um equilíbrio melhor entre recall e precisão, conforme o que for mais crítico para o negócio.
Testar outros algoritmos:
O Decision Tree é um bom começo, mas talvez outros modelos (como Random Forest, XGBoost ou até ensemble de classificadores) tragam resultados melhores nesse trade-off.
Fazer uma análise de custo-benefício:
Se possível, tente quantificar os impactos financeiros dos falsos positivos e falsos negativos. Isso ajuda muito na hora de definir qual métrica priorizar.
Portanto, não dá para dizer se está pronto para produção apenas pelas métricas, mas você já está no caminho certo ao levantar essas reflexões. A decisão final deve considerar tanto os números quanto os impactos reais no negócio.
Espero ter esclarecido.Abraços e bons estudos!
Caso esta resposta tenha lhe ajudado, por favor, marque como solucionado ✓. Bons estudos!