Olá, Cleiton!
Agradeço por compartilhar as imagens e o seu código. Você levantou dois pontos muito importantes, e o primeiro, sobre a ordenação, é um conceito fundamental quando trabalhamos com bancos de dados massivos como o BigQuery.
- Por que o ORDER BY não funciona na tabela final
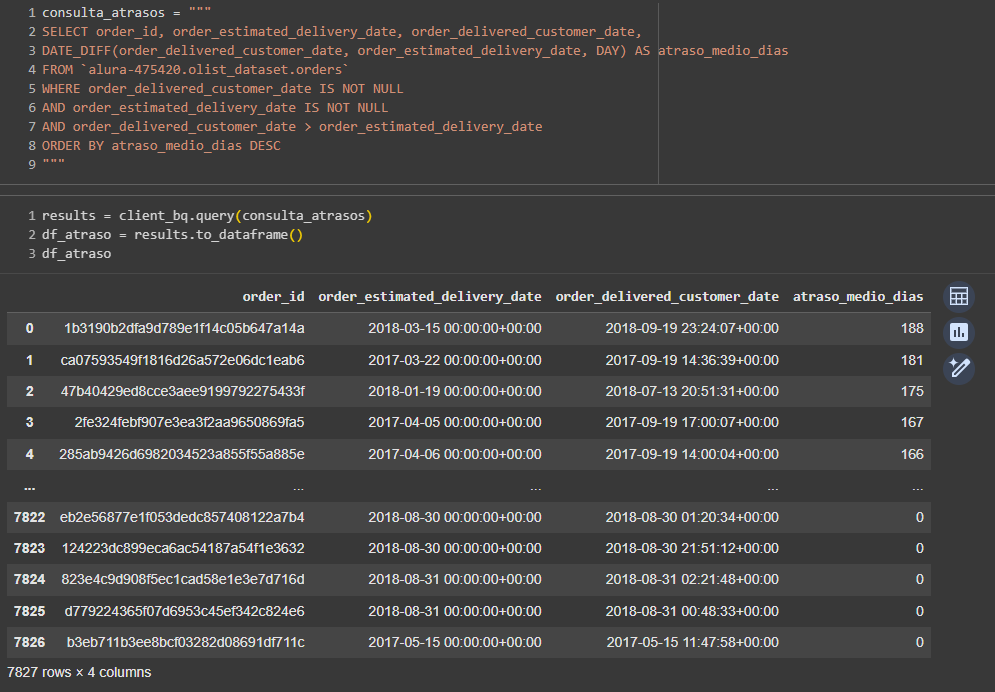
Você está absolutamente correto ao usar o ORDER BY atraso_medio_dias DESC na sua consulta SQL.
O que acontece:
Quando você executa a consulta SQL, o resultado (df_atraso) é um DataFrame do Pandas que está sim ordenado por atraso_medio_dias.
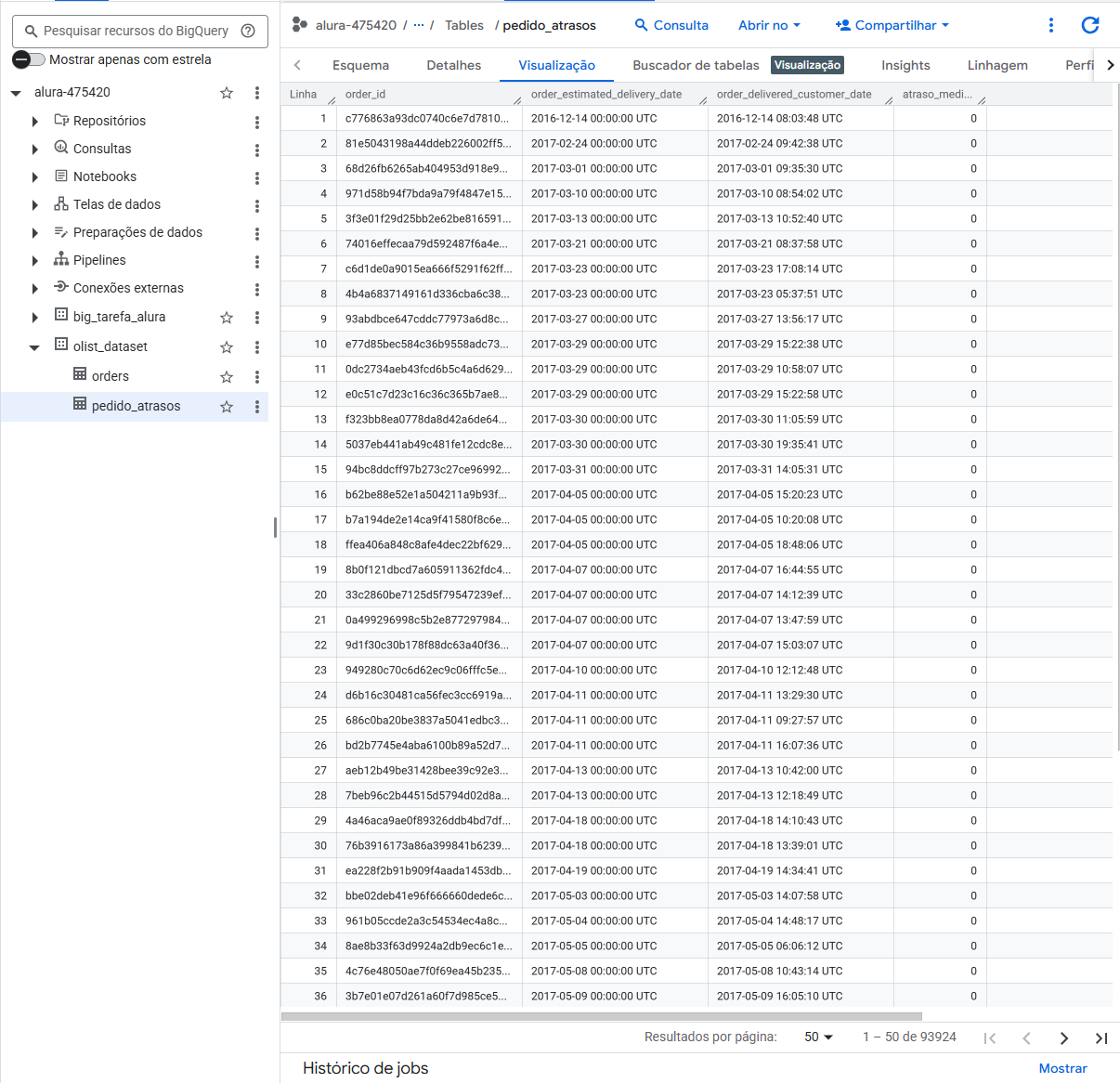
No entanto, quando você carrega esse DataFrame para uma nova tabela no BigQuery (pedido_atrasos), o BigQuery não mantém a ordem de inserção. Sistemas de Data Warehousing como o BigQuery armazenam os dados de forma otimizada para consultas rápidas (query time), não para manter uma ordem física.
O comando ORDER BY que você vê na sua consulta SQL é uma instrução para o resultado da consulta, mas ele não é uma propriedade de armazenamento da tabela em si.
Para resolver (ou confirmar) isso:
Se você quiser ver a tabela pedido_atrasos ordenada no BigQuery, você precisa executar uma nova consulta sobre essa tabela e incluir o ORDER BY nela:
SELECT *
FROM `alura-475420.olist_dataset.pedido_atrasos`
ORDER BY atraso_medio_dias DESC
A ordem que você vê na interface de "Visualização" é apenas a ordem em que os dados foram carregados ou a ordem padrão de exibição, e não a ordem garantida da tabela.
**Correção no Caminho (OBS)
**
Sobre a sua observação do caminho, você está de parabéns por notar e corrigir isso!
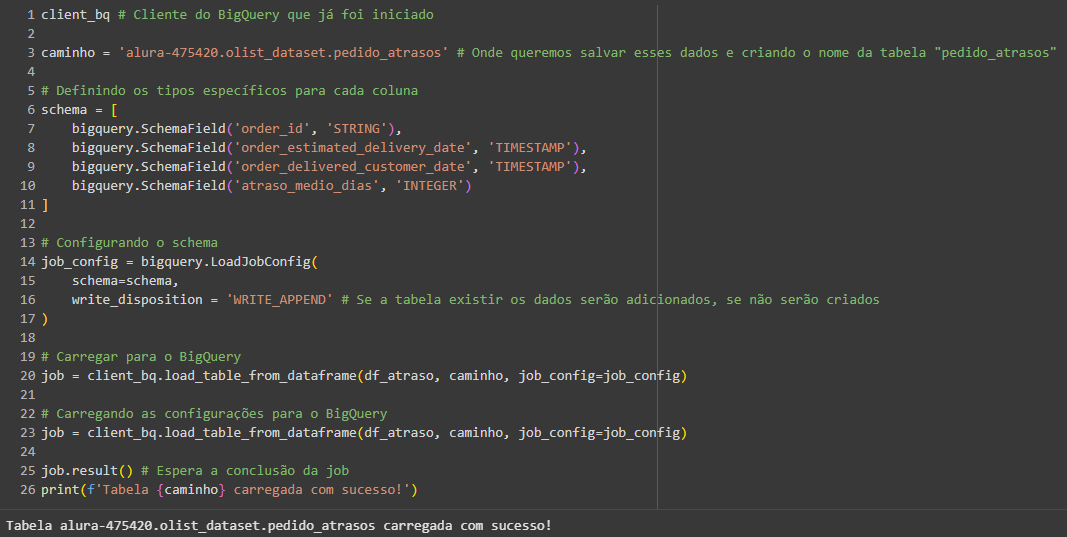
O correto não seria caminho = 'alura-475420.olist_dataset.pedido_atrasos'?
Sim, a correção que você fez, usando olist_dataset em vez de olist_eccomerce na variável caminho, é a correta. Isso acontece porque a estrutura do BigQuery exige o nome exato do dataset (conjunto de dados) para que o client_bq.load_table_from_dataframe funcione.

 )
) )
) )
)
