Essas partes estão no material baixado, mas não na aula:
Quais são suas funções e para contar o número de pedidos em atraso, deve ser usado a função COUNT na consulta atraso?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Essas partes estão no material baixado, mas não na aula:
Quais são suas funções e para contar o número de pedidos em atraso, deve ser usado a função COUNT na consulta atraso?


Olá, William. Como vai?
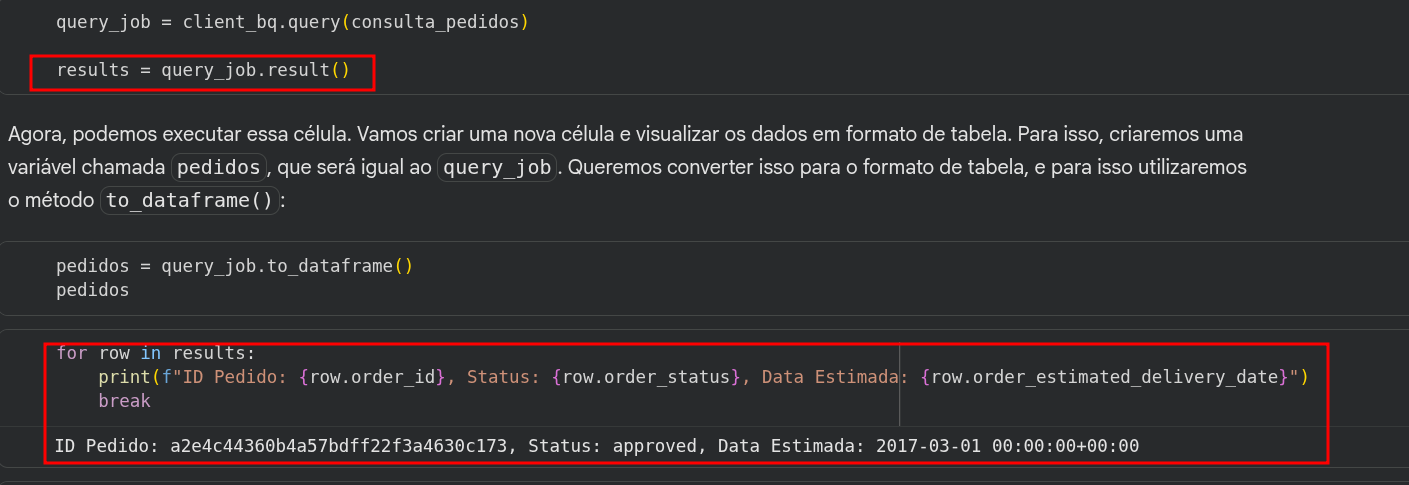
É muito comum que em cursos de Data Science o material de apoio ou os notebooks para download tragam algumas linhas de código extras. Elas servem tanto como um "desafio a mais" para os estudantes quanto para mostrar abordagens alternativas para manipular os mesmos dados.
Vamos destrinchar o que essas linhas destacadas em vermelho estão fazendo e responder à sua dúvida sobre a contagem de pedidos em atraso.
O código que você destacou mostra duas formas diferentes de lidar com os dados retornados pelo Google BigQuery:
results = query_job.result()
results.for row in results:
print(f"ID Pedido: {row.order_id}...")
break
for percorre o objeto results. A palavra-chave break no final é o segredo aqui: ela faz o loop parar imediatamente após ler a primeira linha.order_id, order_status, etc.) vieram com os nomes e formatos corretos.COUNT no SQL?Sim, com certeza! Utilizar a função COUNT diretamente na sua consulta SQL (dentro do BigQuery) é a abordagem mais eficiente e performática no mundo real.
Deixar o BigQuery processar o COUNT poupa memória da sua máquina e banda de internet, pois a nuvem faz todo o trabalho duro e devolve para o Python apenas um número final.
Sua consulta SQL (a variável consulta_pedidos ou uma nova chamada consulta_atrasos) seria estruturada mais ou menos assim:
SELECT COUNT(order_id) AS total_atrasos
FROM `seu_projeto.seu_dataset.seus_pedidos`
WHERE order_status = 'atrasado'
OR order_estimated_delivery_date < order_delivered_customer_date
Como o código do meio da sua imagem converteu os dados em um DataFrame do Pandas (pedidos = query_job.to_dataframe()), você também pode usar o próprio Python para filtrar e contar as linhas, caso já tenha baixado a tabela inteira:
# Filtrando as linhas onde o status é igual a 'atrasado' e medindo o tamanho
total_atrasos = len(pedidos[pedidos['order_status'] == 'atrasado'])
print(f"Quantidade de pedidos em atraso: {total_atrasos}")
Ambas as formas vão te dar exatamente o mesmo resultado numérico, mas focar no COUNT dentro da query SQL original é o que chamamos de boa prática de Query Pushdown (deixar o banco de dados robusto da nuvem fazer o cálculo).
Espero que possa ter lhe ajudado!
Não seria preciso usar o DATE_DIFF junto, assim como na consulta da vídeo aula:
consulta_atrasos = f"""
SELECT
order_id,
order_estimated_delivery_date,
order_delivered_customer_date,
DATE_DIFF(order_delivered_customer_date, order_estimated_delivery_date, DAY) AS atraso_medio_dias -- Calcula o atraso em dias através da diferença entre as datas
FROM
`alura-465911.olist_eccomerce.orders`
WHERE
order_delivered_customer_date IS NOT NULL
AND order_estimated_delivery_date IS NOT NULL
AND order_delivered_customer_date > order_estimated_delivery_date -- Filtra apenas os pedidos que atrasaram, onde a data de entrega é posterior à data estimada
ORDER BY
atraso_medio_dias DESC
"""